
Our English readers are welcome to go directly to the English version Can we work with the fresh data in the Google Search Console Performance Report?
Den meisten ist es vermutlich schon einmal aufgefallen: der GSC-Leistungsreport hat zwei verschiedene Datenzustände. Einer davon sind die aktuellen Daten (im Englischen “fresh data”). Diese werden nach einiger Zeit ersetzt und können von den finalen Daten abweichen. Wie stark weichen Sie denn ab? Und wann sind die Daten in der Regel final? Das wollen wir uns einmal genauer anschauen.
tl;dr
Für alle Profis da draußen, die direkt mit der Überschrift wissen, worum es geht, die wichtigsten Takeaways für die deutsche Zeitzone (Mitteleuropäische Zeit) :
36 Stunden nach dem jeweiligen Tag sind die meisten Datenpunkte (93%) in den von uns betrachteten Daten final.
12 Stunden nach dem zu betrachtenden Tag können die aktuellen Daten der Impressionen, Klicks und der Position genutzt werden. Die Abweichungen sind nur noch sehr gering!
95% der Datenpunkte weisen mindestens 97% der finalen Impressionen auf.
95% der Datenpunkte weisen mindestens 97% der Klicks auf.
95% der Datenpunkte weisen eine maximale Abweichung von 0,4% in der Position auf.
Nutzt die Performancedaten am besten nicht für den gleichen Tag. Es kann passieren, dass ihr mehr Klicks oder Impressionen genannt bekommt, als ihr am Ende in den finalen Daten habt. Kommt selten vor, kann aber wirklich weh tun (Differenzen von + 274%).
Bitte beachtet, dass wir hier aus der deutschen Zeitzone heraus die Daten bewerten, weshalb diese Aussagen für die Mitteleuropäische Zeit (UTC+1) gelten. Die GSC loggt die Daten in Pacific Time (UTC-7). Die Mitteleuropäische Zeit ist also 8 Stunden vor der Pacific Time.
Für unsere internationalen Leser bedeutet dies, dass die angegeben Werte mit der jeweiligen Zeitzone zu verrechnen sind.
Sollte eure Zeitzone also bspw. 9 Stunden vor der Pacific Time sein, müsstet ihr zu unseren Angaben noch eine Stunde addieren – ihr könntet also erst um 13 Uhr am Folgetag von der hier beschriebenen Datenqualität ausgehen (Unschärfen durch die Abfrageintervalle einmal außen vor gelassen).
Wenn ihr eine Stunde hinter der Pacific Time liegt (also UTC -8), dann solltet ihr bereits um 03.00 Uhr des Folgetags die entsprechende Datenqualität vorfinden.
Ihr müsst also immer eure Differenz zu unserer Zeitzone (UTC+1) berechnen und entsprechend zu den Stunden addieren.
Das macht es nun nicht einfacher zu lesen – sorry dafür – das haben wir für die nächsten, internationalen Analysen gelernt ✌️
Danke an Valentin für den extrem wichtigen Hinweis. Auch wenn ich damit einen kleinen Herzinfarkt erlitten habe 😅
Ausführliche Einleitung: was sind aktuelle Daten in der GSC?
Im September 2019 gab es die freudige Info, dass wir im Performance Report der Google Search Console aktuellere Datenpunkte bekommen (https://developers.google.com/search/blog/2019/09/search-performance-fresh-data?hl=en).
Die Freude war damals schnell gedämpft, da es doch einige Einschränkungen gab.
Google stellt direkt klar, dass die Daten nicht unbedingt mit den finalen Daten übereinstimmen müssen. “Each fresh data point will be replaced with the final data point after a few days. It is expected that from time to time the fresh data might change a bit before being finalized.” Schreckt erstmal ab – schließlich will man seine Einschätzungen nicht wieder revidieren müssen, da sich die Datenlage ändert.
Die Verfügbarkeit über API war nicht gegeben. Eine Einschränkung, die zumindest Profis schnell dazu gebracht hat, das Feature mehr oder weniger zu ignorieren.
Für die Discover-Daten gab es erstmal keine aktuellen Daten.
Die gute Nachricht ist, 2019 ist ja schon ’ne Weile her ( Stand heute ca. 3 Monate + irgendwelche Corona-Jahre, die sich nicht mehr so genau beziffern lassen 😅). Seit dem hat sich Einiges getan und seit Dezember 2020 bekommen wir die aktuellen Daten auch via API (https://developers.google.com/search/blog/2020/12/search-console-api-updates?hl=en, Details dazu unter https://developers.google.com/webmaster-tools/v1/searchanalytics/query?hl=en) und für Discover sind die Daten nun auch aktuell.
Wenn ihr gar nicht so genau wisst, wovon ich rede. Dann schaut doch einfach mal in eure Search Console. Meist ist der aktuellste Tag im Graphen noch mit einem Vermerk versehen (mit der Maus einfach über die Linien fahren).
Über die Filter wird nochmal deutlich darauf hingewiesen.
Neu ist ja immer relativ – wenn wir die Corona-Jahre wirklich nicht zählen, können wir das nochmal durchgehen lassen ![]()
Zu den möglichen Abweichungen steht in der aktuellen Doku (https://support.google.com/webmasters/answer/7576553?hl=en, Stand 09.03.2023) Folgendes:
The newest data in the Search Performance report is sometimes preliminary – this means that the data might change slightly before it is confirmed. Preliminary data is usually less than three days old; at some point, all preliminary data is confirmed. Preliminary data is indicated when you hover over it in the chart.
Preliminary data is included in both the chart and the tables for Search performance, as well as the Performance chart in the Search Console Overview page.
Das bringt uns dann zur eigentlichen Frage.
Google sagt, es kann leichte Abweichungen geben. Ist die Datenqualität der aktuellen Daten so gut, dass wir sie in der alltäglichen Arbeit nutzen können?
Schließlich gibt es ja doch ein paar spannende Usecases, wie:
ein kleines Ranktracking auf den GSC-Daten bauen,
Bugfixes beobachten und früh sehen, ob es wirklich besser wird, oder
bei besonders wichtigen Kampagnen doch etwas früher die Performance auf den SERP auswerten, als mit mindestens 2 Tage Versatz.
Dieser Frage haben wir uns gestellt und nehmen euch gern mit auf die Erkundungsreise.
Das Datenset
Wir haben einmal einen kleinen Ausschnitt unserer verfügbaren Properties zusammengezogen. Die von uns betrachteten Daten haben folgende Eigenschaften:
Zeitraum: 01.01.2023 – 28.02.2023
89 Properties – davon 44 Publisher-Seiten, 9 Shops und 36 andere Seiten (Dienstleistung u.Ä.).
Die Abfrage hat auf der Propertyebene stattgefunden (aggregationType =
byProperty).Wir betrachten dabei nur die Suchen für den jeweiligen Zielmarkt – in diesem Fall nur deutschsprachige Seiten für DEU, CHE, und AUT (Filter über
country).Abgefragt wurde nur der Searchtype
web.Wir betrachten das Ganze unabhängig von den Dimensionen Device oder Search Appearance.
Damit ihr noch ein besseres Gefühl für das Datenset bekommt und wir zudem auch ein paar Segmentierungen an unsere Betrachtungen anlegen können, haben wir noch folgende Bins gebildet:
nach Anzahl der rankenden Seiten
nach Anzahl der rankenden Suchanfragen
nach der Summe der Klicks
nach der Summe der Impressionen
 (Für die Ansicht der Mediendatei einfach auf’s Bild klicken.)
(Für die Ansicht der Mediendatei einfach auf’s Bild klicken.)
Zu jeder unserer Analysen haben wir diese Segmente ebenfalls zu Rate gezogen und geschaut, ob sich daraus weitere Einsichten ergeben. Wir kommen im Folgenden darauf zurück, wenn es relevant ist.
Wie haben wir die aktuellen Daten erhoben?
Unsere Untersuchungsdaten haben wir aus unserer bestehenden Datenpipeline abgezweigt. Daher waren wir auf die folgenden Intervalle beschränkt.
03.00 Uhr
12.00 Uhr
21.00 Uhr
Ihr könnt euch vorstellen, dass die Erhebung natürlich nicht für alle Properties zum exakt gleichen Zeitpunkt stattfindet. Entsprechend haben wir auf die oben benannten Uhrzeiten gerundet.
Das Datenset sieht für ein Date einer Property bspw. so aus:
 (Für die Ansicht der Mediendatei einfach auf’s Bild klicken.)
(Für die Ansicht der Mediendatei einfach auf’s Bild klicken.)
Ihr seht hier die Daten für eine gegeben Property für den 26.01.2023 (date). Zum ersten mal haben wir die Daten am selben Tag um 21:00:00 (load_date) abgefragt. date_end ist eine Hilfsspalte, die die letzte Minute des betrachteten Tages enthält und anhand derer die Differenz in Stunden der einzelnen Ladeintervalle (hours_diff) berechnet werden kann. Die clicks und impressions geben die jeweiligen Werte an, die wir beim jeweiligen Ladeintervall von der API zurückerhalten haben. pct_clicks und pct_impressions geben den Anteil der aktuellen Clicks / Impressions an den finalen Werten an.
So viel zum beschreibenden Vorgeplänkel. Kommen wir zu den spannenden Fragen!
Wann sind die Daten in der Regel final?
Kurzer Reminder an Googles Angabe:
Preliminary data is usually less than three days old; at some point, all preliminary data is confirmed.
Stimmt diese Aussage für unseren Erhebungszeitraum oder haben wir vielleicht Datenpunkte, die noch länger als 3 Tage brauchen?
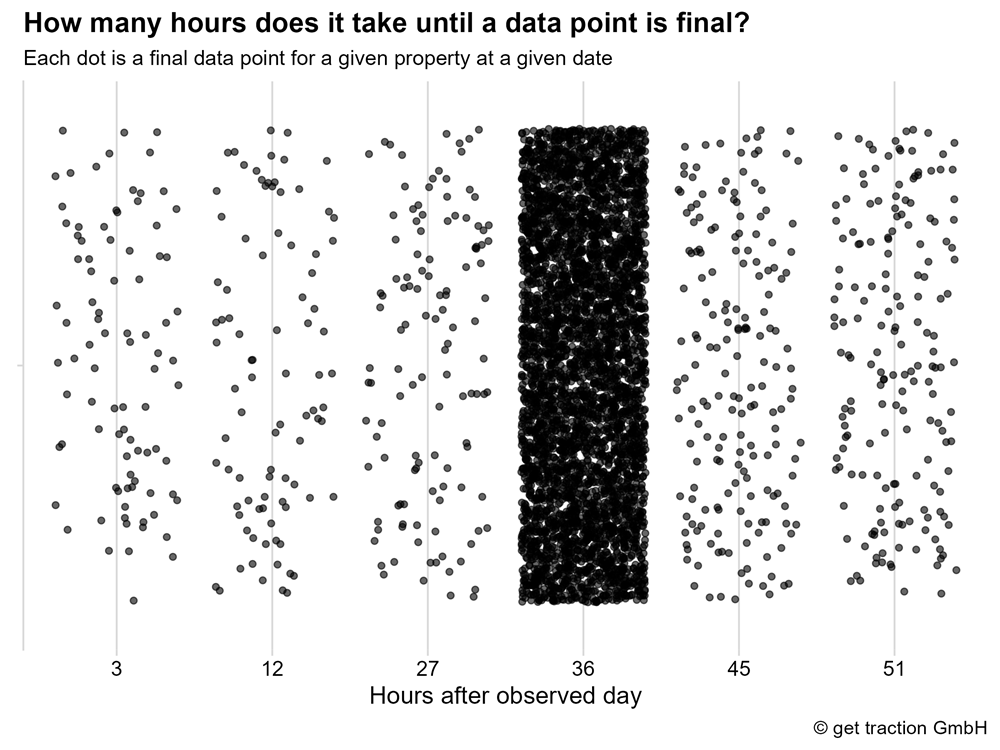
Jeder Datenpunkt entspricht hier einer Property- und Datumskombination für einen finalen Datenpunkt.
Was wir hier sehen ist, dass es sogar einige Datenpunkte gibt, die bereits nach 3 Stunden final sind. Aber die klare Mehrheit sammelt sich bei 36 Stunden.1 Die letzten finalen Datenpunkte sind 51 Stunden nach dem betrachteten Tag zusammengekommen – also deutlich unter 3 Tagen. Google hat im Betrachtungszeitraum sein Versprechen gehalten.
Um es konkret zu machen:
Nach 36 Stunden sind 93% der betrachteten Datenpunkt final.
Natürlich haben wir uns das auch nach den jeweiligen Bins – ihr erinnert euch Anzahl Queries, Anzahl Pages, Summe der Klicks und Summe der Impressionen – betrachtet. Dabei gab es keine Auffälligkeiten, also alles easy.
Das ist aber ja auch nur der erste Schritt in der Betrachtung. Gehen wir direkt weiter.
Wie unterscheiden sich die aktuellen und finalen Datenpunkte?
Oder mal ganz operativ ausgedrückt: Sind die aktuellen Daten denn überhaupt nutzbar?
Können wir denn schon nach 3 Stunden mit den aktuellen Daten arbeiten oder sollten wir immer auf die finalen Daten nach ca. 36 Stunden warten?
Abweichung der Impressionen der aktuellen GSC-Daten
Betrachten wir also einmal, wie sich die Impressionen der aktuellen Daten verhalten.
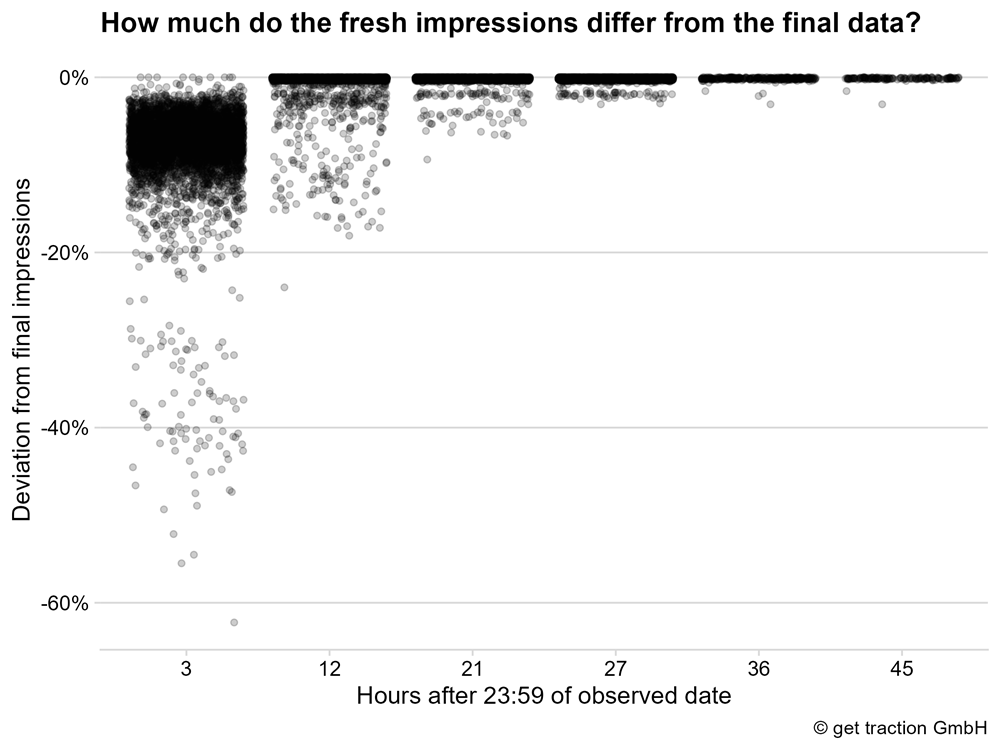
Wir sehen, dass die Impressionen nach 3 Stunden in den meisten Fällen weniger als -20% von den finalen Impressionen abweichen. Umgekehrt ausgedrückt: Der Wert der meisten aktuellen Datenpunkte entspricht nach drei Stunden bereits zu mindestens 80% den Impressionen, die für die Datenpunkte als finaler Wert ausgewiesen werden.
Nicht schlecht – ehrlicherweise haben wir angenommen, dass die Quote deutlich schlechter ist.
Nach 12 Stunden sammeln sich die Punkte schon vermehrt bei einer Abweichung von nahezu 0%. Schauen wir uns die Verteilung im Detail an um es ganz klar zu erfassen.
 (Für die Ansicht der Mediendatei einfach auf’s Bild klicken.)
(Für die Ansicht der Mediendatei einfach auf’s Bild klicken.)
Eine kurze Leseanleitung anhand der ersten Zeile – Zelle für Zelle:
3 Stunden nach dem betrachteten Tag (hours_diff),
haben wir 4.976 aktuelle Datenpunkte (n) erhalten.
Der Datenpunkt mit dem geringsten Anteil an den finalen Impressionen (
min), hat 37,75% seiner eigenen finalen Impressionen aufgewiesen.Hättet ihr also einen finalen Datenpunkt mit 1.000 Impressionen, könntet ihr im Worstcase nach 3 Stunden nur 377 Impressionen ausgewiesen bekommen.
Das erste Percentil (p01), also die ersten 1% der beobachteten Datenpunkte, aufsteigend sortiert vom geringsten Anteil zum höchsten, weist maximal 62,97% der finalen Impressionen auf.
bedeutet der “beste” Datenpunkt des ersten Percentils erreicht 62% der Impressionen, alle anderen liegen darunter – der Mindestwert liegt bei den bereits benannten 37,75%.
Umgekehrt ausgedrückt: alle weiteren 99% der beobachteten Datepunkte weisen mehr als 62,97% der finalen Impressionen auf.
Die ersten 5% der beobachten Datenpunkte (p05, aufsteigend sortiert vom geringsten Anteil zum höchsten), weisen maximal 85,93% der finalen Impressionen auf.
und so weiter…
Für uns hat sich dabei ein Punkt als sehr stabil gezeigt.
Nach 12 Stunden erreichen die ersten 5% der Datenpunkte, maximal 97% der finalen Impressionen. Das bedeutet, dass die andereren 95% der Datenpunkte mindestens 97% der finalen Impressionen aufweisen. Stabile Basis, würden wir sagen und halten Folgendes fest:
12 Stunden nach dem zu betrachtenden Tag, können die aktuellen Daten der Impressionen genutzt werden. Die Abweichungen sind nur noch sehr gering!
Machen wir die Prüfung auch nochmal mit den Klicks.
Abweichung der Klicks in den aktuellen GSC-Daten
Ihr kennt das Vorgehen – daher etwas knapper.
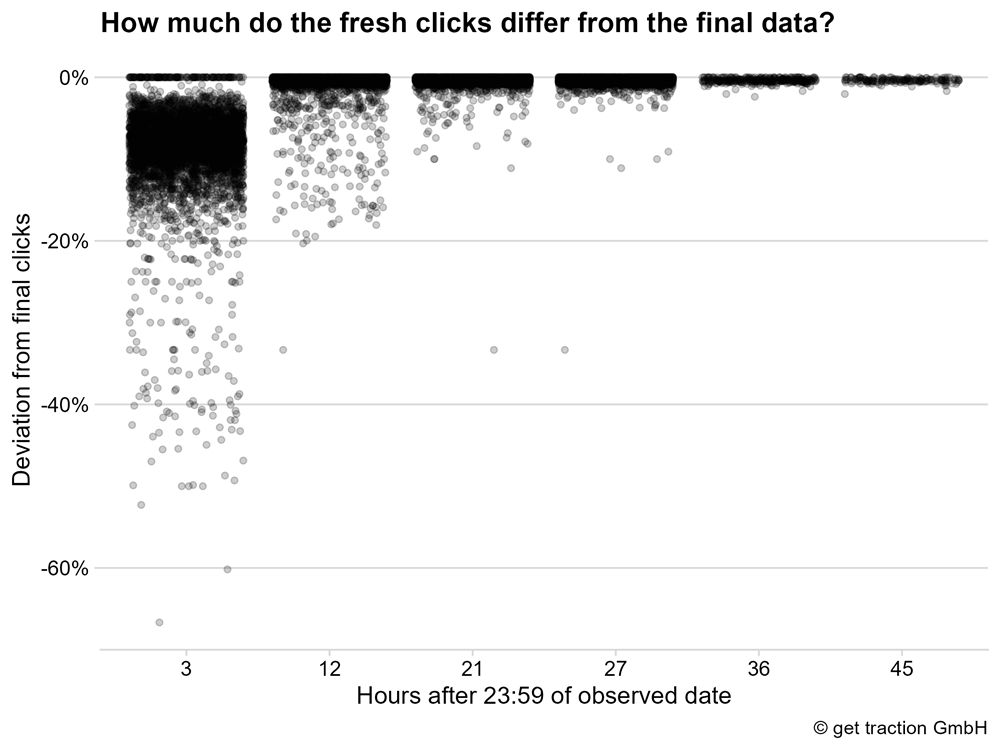 Wir sehen hier das gleiche Bild. Nach 3 Stunden weist die Mehrheit der betrachteten Datenpunkte weniger als -20% Abweichung zu den finalen Daten auf. Nach 12 Stunden sammelt es sich wieder vermehrt bei einer Abweichung von nahezu 0%.
Wir sehen hier das gleiche Bild. Nach 3 Stunden weist die Mehrheit der betrachteten Datenpunkte weniger als -20% Abweichung zu den finalen Daten auf. Nach 12 Stunden sammelt es sich wieder vermehrt bei einer Abweichung von nahezu 0%.
 (Für die Ansicht der Mediendatei einfach auf’s Bild klicken.)
(Für die Ansicht der Mediendatei einfach auf’s Bild klicken.)
In der Tabelle sehen wir: Nach 12 Stunden weisen 95% der Datenpunkte mindestens 97,05% der Klicks auf.
Die Abweichungen zu den Impressionen sind nicht wesentlich. Wir kommen auf das gleiche Ergebnis.
12 Stunden nach dem zu betrachtenden Tag, können die aktuellen Daten der Klicks genutzt werden. Die Abweichungen sind nur noch sehr gering!
Abweichung der Position in den aktuellen GSC-Daten
Da ein kleines Ranktracking ja ebenfalls eine spannende Anwendung der Daten sein kann, schauen wir uns die aktuellen Positionen einmal im Detail an.
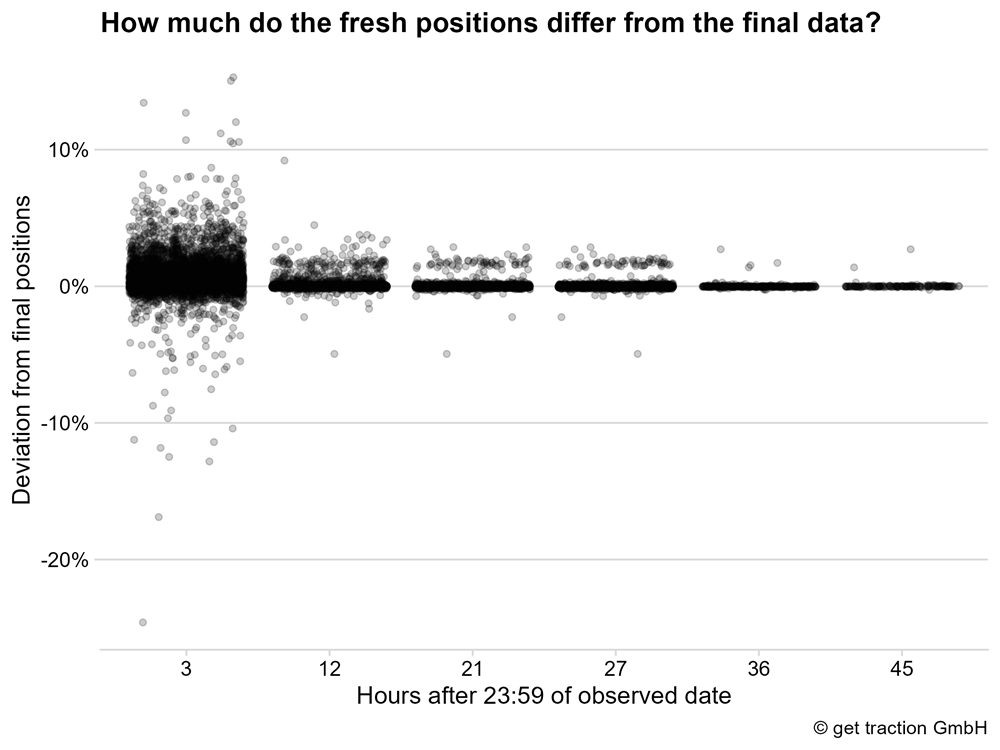
Die Grafik zeigt, dass wir vor allem nach 3 Stunden noch einige Abweichungen haben. Insgesamt geht dabei der Trend eher in Richtung eines schlechteren Rankings – die Abweichung ist also positiv. Ein Beispiel: Wird das Ranking nach drei Stunden mit Position 11 angegeben, die finale Position des Rankings ist allerdings 10, dann besteht eine Abweichung von 10% in der Position.
Für die Verteilungstabelle haben wir noch eine kleine Transformation der Daten vorgenommen. Wir betrachten nur noch die prozentuale Abweichung der Position, unabhängig vom Vorzeichen (+ oder -). Dieser kleine Trick war notwendig, da wir die Abweichungen ansonsten in keine sinnvolle Reihenfolge bringen können, um die Percentile zu berechnen.
 (Für die Ansicht der Mediendatei einfach auf’s Bild klicken.)
(Für die Ansicht der Mediendatei einfach auf’s Bild klicken.)
So haben wir bspw. nach 3 Stunden für die ersten 1% der Datenpunkte eine Abweichung von maximal 6,2%. Bedeutet, dass wir bereits hier für die anderen 99% der Datenpunkte eine Abweichung von unter 6,2% festellen können.
Nach 12 Stunden weisen 95% der Beobachtungen eine maximale Abweichung von 0,4% auf.
Lasst uns gar nicht weiter drüber reden. Für die Metrik Position sind die Abweichungen generell nicht sehr stark und 12 Stunden nach dem jeweiligen Datum liegt keine nennenswerte Abweichung mehr vor.
Die Positionsdaten weichen insgesamt am geringsten ab. Nach 12 Stunden liegt die Abweichung maximal bei 0,4% – also kaum erwähnenswert!
Abweichungen nach Bins
So weit, so gut. Der aufmerksame Leser fragt sich, warum bisher noch keine Infos zu den oben gebildeten Bins kamen. Naja, es hat nie einen deutlichen Unterschied gegeben. Meint:
Egal, ob eure Webseite groß oder klein ist, ihr seid nicht mehr oder weniger von den Abweichungen betroffen.
Lasst uns aber der Vollständigkeit halber gerne zusammen als Beispiel auf die Abweichung der Impressionen in den vier Bins schauen.
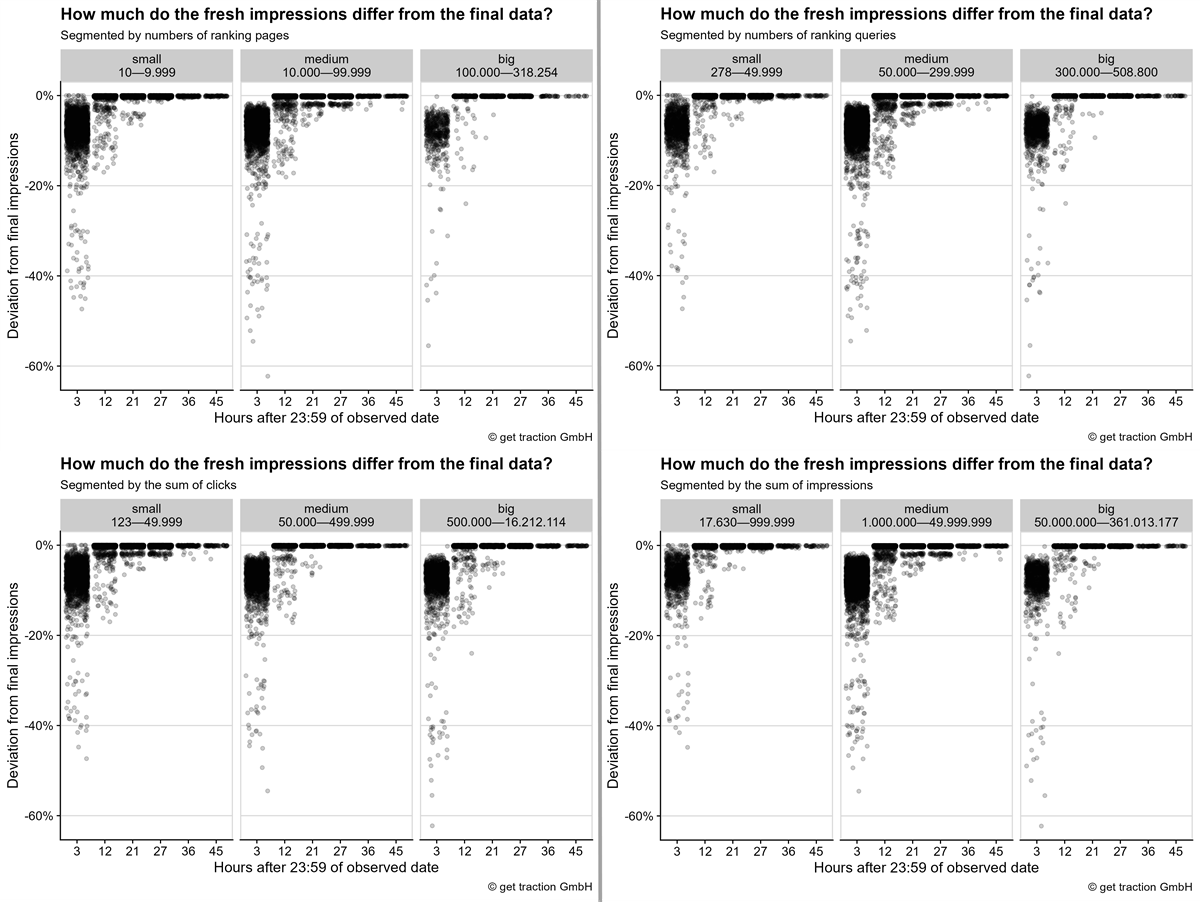 (Für die Ansicht der Mediendatei einfach auf’s Bild klicken.)
(Für die Ansicht der Mediendatei einfach auf’s Bild klicken.)
Bitte bedenkt, dass die Anzahl der Datenpunkte je Bin unterschiedlich ist. Daher gibt es mal mehr Punkte auf den Randbereichen, wenn insgesamt mehr Datenpunkte in den Bin fallen. Anteilig gab es keine wesentlichen Auffälligkeiten. Wenn man unbedingt möchte, könnte man festhalten, dass es bei kleinen Webseiten nach 3 Stunden häufiger aktuelle Datenpunkte gibt, die bereits 100% der finalen Impressionen entsprechen. Allerdings ist dies so eine geringe Anzahl, dass es in der Praxis wenig Relevanz hat.
Aktuelle Datenpunkte mit mehr als 100% der finalen Daten
Als kleine Randnotiz möchten wir euch natürlich nicht vorenthalten, dass wir mit dem obigen Datenset auch noch ein wenig geflunkert haben ![]()
Die obige Auswertung sollte nicht erklärungsaufwändiger gemacht werden, als sie so schon ist. Daher haben wir aktuelle Datenpunkte mit mehr als 100 % der finalen Daten zur Vereinfachung erstmal rausgefiltertert und ans Ende gehängt.
Wie ihr vermutlich auch, haben wir erwartet, dass die aktuellen Datenpunkte immer nur ein Teil der finalen Summe sind. So in der Denke “es kommen schrittweise mehr Daten dazu”. Stimmt auch – fast immer.
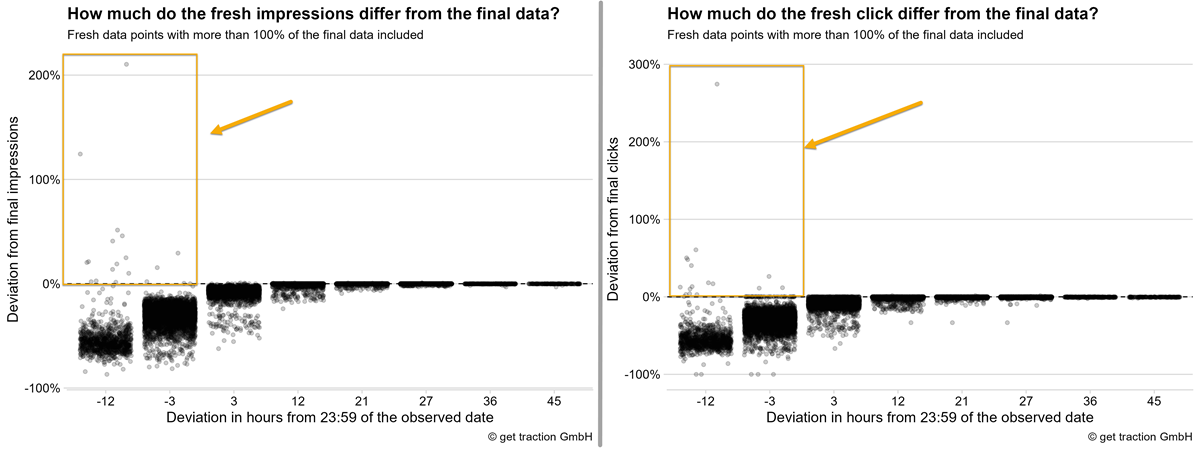 (Für die Ansicht der Mediendatei einfach auf’s Bild klicken.)
(Für die Ansicht der Mediendatei einfach auf’s Bild klicken.)
Wie ihr nun erkennen könnt, gibt es einige Datenpunkte, die deutlich über den finalen 100% der Klicks oder Impressionen liegen. Bei den Klicks handelt es sich um 33 Datenpunkte, bei den Impressionen um 102 Datenpunkte.
Diese treten immer auf, wenn ihr euch die Daten für den gleichen Tag anschaut – also bspw. um 12 Uhr am 10.03.2023 prüft, wie viele Klicks es für ebendiesen Tag gibt.
Um es noch etwas greifbarer zu machen. Die stärkste Abweichung bei den Klicks war bspw. 274% der finalen Daten. In absoluten Zahlen war dies eine Differenz von 19.271 Klicks. Ihr würdet also davon ausgehen, dass ihr “bisher” 26.293 Klicks für den Tag habt. Wenn die Daten aber final sind, bleiben euch nur noch 7.022 übrig 🤯
Die Fallzahlen sind zwar recht gering, aber so etwas ist immer eine unschöne Überraschung und ein Risiko, wenn ihr “zu gute Zahlen” vielleicht sogar an eure Chefetage weitergebt.
Ihr solltet also bis zum Folgetag warten, bevor ihr die GSC-Performance-Daten nutzt.
Grundsätzlich hätten wir uns eine gewisse Abweichung in dieser Richtung mit Datenschutz und der Bereinigung besonders seltener Suchanfragen erklären können (siehe https://support.google.com/webmasters/answer/7576553?hl=en , Absatz “Data discrepancies”). Die maximalen Abweichungen lassen sich aber vermutlich nur schwer damit erklären.
Eine kleine Methodenkritik
Während wir so die Daten aufbereitet haben, sind uns natürlich noch einige weitere Ideen gekommen.
Spannend wären die Betrachtungen mit der Beobachtung der Metriken Anzahl an rankenden Seiten und Anzahl verschiedener Suchanfragen. Damit würden wir quasi die Fragen beantworten:
Inwieweit weisen die aktuellen Daten eine andere Anzahl von rankenden Seiten auf?
Fehlen tatsächlich Seiten oder ändert sich nur die Summen der vorhanden Klicks und Impressionen?
Inwieweit weisen die aktuellen Daten eine andere Anzahl von verschiedenen Suchanfragen auf?
Fehlen eher ganze Anfragen oder ändern sich nur die vorhanden Summen der Klicks und Impressionen?
Gibt es Unterschiede bei den Properties mit einem eher diversen Anfrageprofil (viele unterschiedliche Anfragen, eher Longtail vs. wenige unterschiedliche Anfragen)?
Gibt es Unterschiede bei der Betrachtung besonders brandlastiger Seiten vs. weniger brandgetriebenen?
Schnell als spannende Fragen in den Raum geworfen. Aber nicht ganz so schnell gemacht, da wir das Datenset nochmal vollständig tauschen und ein paar Millionen Zeilen mehr durch die Gegend schubsen müssten. Wir glauben, dass die ersten Einsichten hier ausreichend sind um klar zu wissen, wie man die Dinge im Alltag handlen muss. Schließlich hat die Betrachtung nach den bisher gebildeten Bins auf der Property-Ebene auch keine Einsichten gebracht, die darauf hinweisen, dass die benannten Punkte noch einen Unterschied mit sich bringen könnten. Solltet ihr das aber spannend finden und noch mehr Fragen dazu haben, dann macht einfach etwas Lärm. Wenn ihr laut genug seid, dann setzen wir uns vielleicht auch nochmal dran!
Das Fazit sparen wir uns an dieser Stelle, da ihr es bereits oben im tl;dr gelesen habt.
Danksagung
Das Wichstigste zum Schluss: Zwar bin ich hier der Autor des Artikels, habe ihn ausgedacht und runtergetippt. Aber ein besonders großer Teil der Arbeit war vor allem die Datenerhebung und Aufbereitung. Das hätte ich niemals ohne meinen Kollegen Patrick hinbekommen. Wir haben stundenlang geslacked und nachgedacht, während er die Daten direkt in R durch die Gegend geschubst hat. Seine Aufbereitungsskills haben den Artikel überhaupt erst möglich gemacht. Ansonsten wäre es wohl bei der Idee geblieben. Ein weiterer Dank geht auch an Johannes Kunze, der uns an der ein oder anderen Stelle auf die richtige Fährte geschubst hat und sowieso unsere Dateninfrastruktur hingesetzt hat, auf der alles basiert.
Danke Jungs! ❤️
Fußnoten:
1 Bedenkt dabei allerdings, dass wir nur bestimmten Intervallen Abfragen. Prinzipiell bestünde also die Möglichkeit, dass die Mehrheit der Daten schon nach 28 Stunden da ist, wir sie aber erst nach 36 Stunden holen.

Stefan Keil
GESCHÄFTSFÜHRENDER GESELLSCHAFTER
Gründer und Geschäftsführender Gesellschafter der get traction GmbH mit einem ❤️ für strukturierte Prozesse, geiles Monitoring und tiefe, analytische Aufgaben.




2 Kommentare:
Moin Stefan, schöner Artikel. Das deckt sich mit meinen Beobachtungen.
Bei den URLs zumindest im Discover-Bericht habe ich massive Unterschiede in der Anzahl der URLs innerhalb der ersten 24h festgestellt.
Spannend wäre auch, inwieweit sich die aggregierten Zahlen von den Detail-Zahlen (URL/Query) in Bezug auf die gefilterten/anonymisierten Daten unterscheiden.
Bei den Zeitzonen muss man immer vorsichtig sein. PST wird am zweiten Sonntag im März zu PDT (Daylight Time). CET/MEZ wird aber erst am letzten Sonntag im März zu CEST/MESZ. In dem Zeitraum dazwischen sind die Unterschiede dann andere. (Die Daten habe ich aus dem Hinterkopf geholt. Bitte vor Nutzung validieren) 😉
Hi Johan,
danke für deinen Kommentar!
Wir sind am überlegen, ob wir uns das für Discover auch nochmal anschauen. Bisher haben wir auch das Gefühl, dass es sich etwas anders verhält, aber noch nicht ganz in dieser Form aufbereitet.
Den Punkt zu den Detailzahlen hatten wir ja auch in der Methodenkritik erwähnt. Wir schauen mal, ob wir den Weg noch gehen – ist halt wieder ein komplett neues Datenset. Muss man schauen, ob ich Patrick und auch mich nochmal animiert bekomme 😉
Ja, die Zeitzonen hatten uns nochmal kalt erwischt 🤦♂️ Für die tägliche Arbeit in DE kann man das erstmal so stehen lassen. Der Rest ist doch etwas komplizierter in der Rumrechnerei…
Bis vielleicht die Tage auf der SMX ✌️