Google Discover ist für Verlage die größte Traffic-Quelle im Google-Kosmos. Dennoch ist Discover leider immer noch eine Black Box. Alles, was man als SEO zur Optimierung benötigt, wie Rankings, Suchvolumen, Informationen über die Konkurrenz etc. fehlt.
Die einzige Quelle für Leistungswerte ist der Report aus der Google Search Console. Leider ist dieser rudimentär. Wir bekommen ausschließlich URLs sowie die Leistungswerte der URLs zu einem Datum. Da aber täglich andere URLs in Discover funktionieren, kann man aus diesem Report keine Handlung ableiten. Discover-Traffic kommt oder kommt halt nicht. Wenn der Traffic ausbleibt hilft der Report wenig die Gründe zu erkennen.
Aus diesem Grund analysieren wir den Traffic unserer Verlagskunden intensiv in unserem Google Discover Performance Dashboard. Hierzu senden wir alle URLs aus dem GSC-Discover Leistungsreport auf Tagesbasis an die Google NLP-API und lassen uns die erkannten Entitäten zurückgeben. Auch wenn uns klar ist, dass Google nicht die öffentlich verfügbare NLP-API nutzen wird, bekommen wir einen Eindruck daraus, welche Themen pro Blatt funktionieren. Welche thematischen Autoritäten vorliegen, ob diese nach Updates von Google noch vorhanden sind oder ob der Versuch, neue Autoritäten zu erarbeiten, Erfolg zeigt.
Mehr zu unserem Vorgehen findet ihr bei Interesse in unserem Artikel Google Discover-Traffic analysieren – Was haben wir gelernt?
In den letzten 12 Monaten haben wir über 1,4 Mrd. Klicks und 15,8 Mrd. Impressionen analysiert und in Entitäten zugeordnet.
Top Discover Entitäten – was wird oft ausgespielt?
Trotz unseres großen Datenbestands sind unsere Top-Entitäten nicht repräsentativ. Wir haben zwar fast 30 Verlagsangebote im Datenbestand, von denen über 10 zu den IVW-Top 100 gehören, dennoch ist es kein repräsentativer Schnitt der deutschen Verlage.
Für mich ist aber einiges Lehrreiches dabei:
Zum einen sehen wir Entitäten, die selbst eher für eine Art von Interesse und nicht ein konkretes Interesse stehen. Ein gutes Beispiel ist hier Instagram. Instagram steht hier nicht für ein allgemein großes Interesse an Instagram, sondern für ein Interesse von Inhalten, die auf Instagram von entsprechend Prominenten geteilt wurde.
Wenn man eine Kookkurrenzanalyse über Entitäten, die zusammen mit Instagram in Artikeln vorkommen, durchführt, dann findet man viele mehr oder weniger bekannte Personen. Hier ist zu vermuten, dass eben diese Personen das eigentliche Interesse darstellen.
Andere Entitäten haben mich hingegen überrascht, da diese in meinem Discover-Feed keine Rolle spielen. Wie beispielsweise die großen Handelsketten wie Aldi, Lidl, Edeka und Co. Wobei hier spannend zu sehen ist, dass diese überwiegend zusammen mit Angebot und gegebenenfalls dem konkret angebotenen Produkt vorkommen. So viel zur Kommerzialisierbarkeit von Discover.
Discover Feed prüfen – was wird wie ausgespielt
Wenn wir über den Umweg der Entitätenerkennung und Zuordnung wissen, welche Themen für uns wichtig sind, können wir diese bewusst und verstärkt spielen. Eine einfache Taktik: Mach mehr von dem, was funktioniert!
Wichtige Hebel sind hierbei:
- Relevante und klickattraktive Headline
- Gute Bilder. Diese sollten in den drei von Google geforderten Formaten vorliegen und ebenfalls klickattraktiv sein
- Republishing ist Dein Freund, mehr dazu auch in dem oben verlinkten Artikel
Aber wie kann ich jetzt prüfen, wie ich in Discover dargestellt werde? Und was genau machen eigentlich meine Marktbegleiter?
Dazu gab es vor gut einem Monat auf Twitter einen Tweet mit einer kurzen Anleitung. Vielen Dank an dieser Stelle an @DeiviZzZ für das Teilen! Und folgt ihm gerne.
Zuerst müsst ihr in Chrome die Entwicklertools öffnen. Entweder per Tastenkombination Strg + Shift + I oder im Menü:
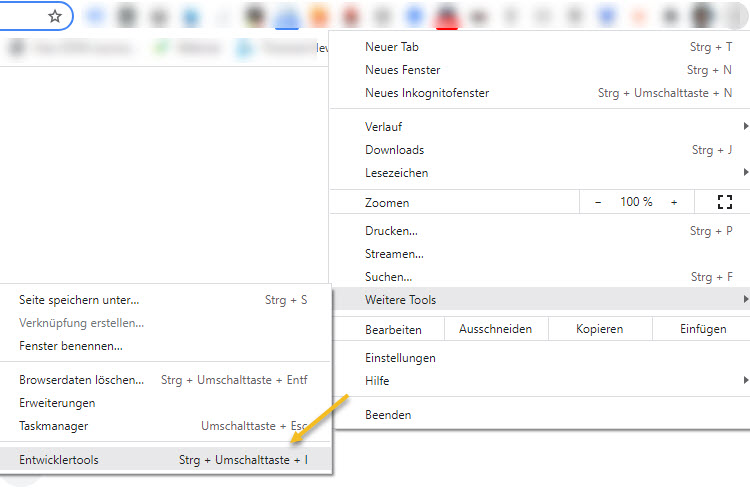
Dann schaltet ihr die Ansicht auf Mobile um:

Jetzt, und erst jetzt, könnt ihr folgende URL nutzen, um euch Discover-Ergebnisse zu einem Suchbegriff anzeigen zu lassen:
Hierbei ist
- hier q= die Suchanfrage zu erfassen
- hl= gibt die Sprache an
- qdr: gibt den Zeitraum an. Hierbei steht d für letzter Tag, w für letzte Woche, m für letzten Monat und y für letztes Jahr
Hier ein Beispiel für Horoskop. Spannend ist hierbei, dass Google teilweise verwandte Begriffe anzeigt:

Vor allem aber können wir jetzt prüfen, welche Formulierungen und Inhaltsarten zum Thema Horoskope stattfinden. Wir können auch prüfen, welche Art von Bildern verwendet werden. Da Horoskope ein sehr gut planbares Thema sind, kann ich also Hypothesen entwickeln und diese testen.
Wichtig ist hierbei aber, dass der Suchbegriff möglichst den Entitäten entspricht, die Google vorrangig nutzt. Hier ein Vergleich zwischen SGE und Eintracht Frankfurt:
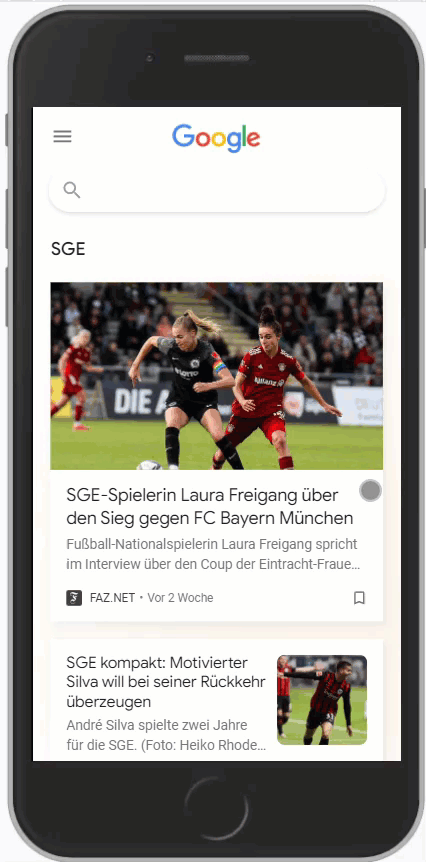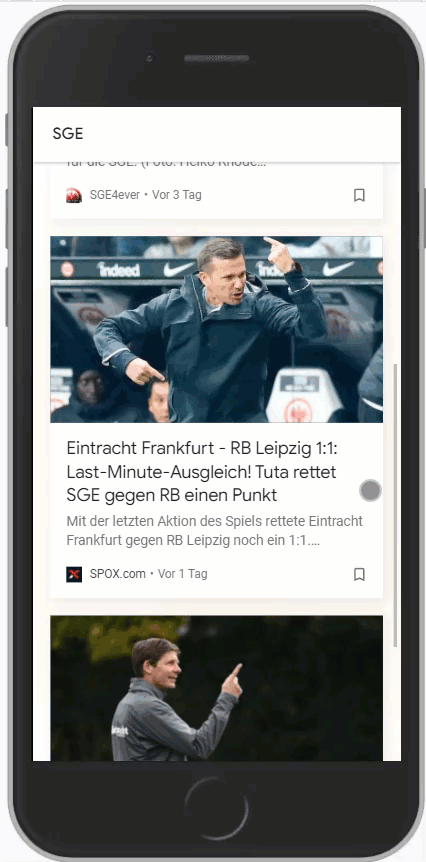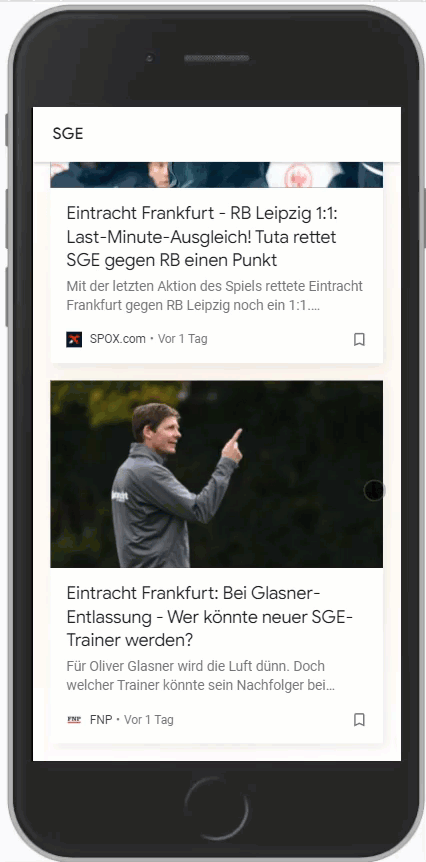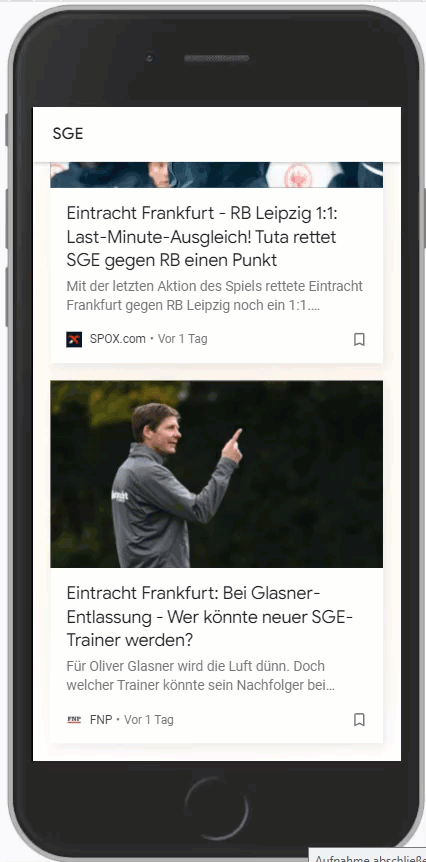
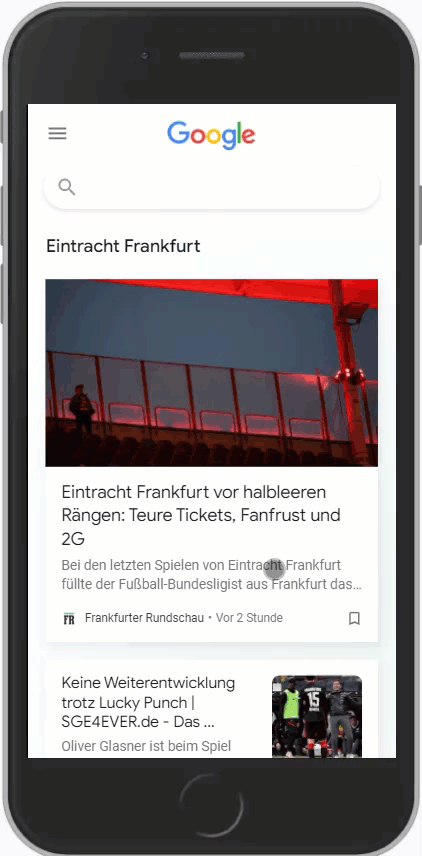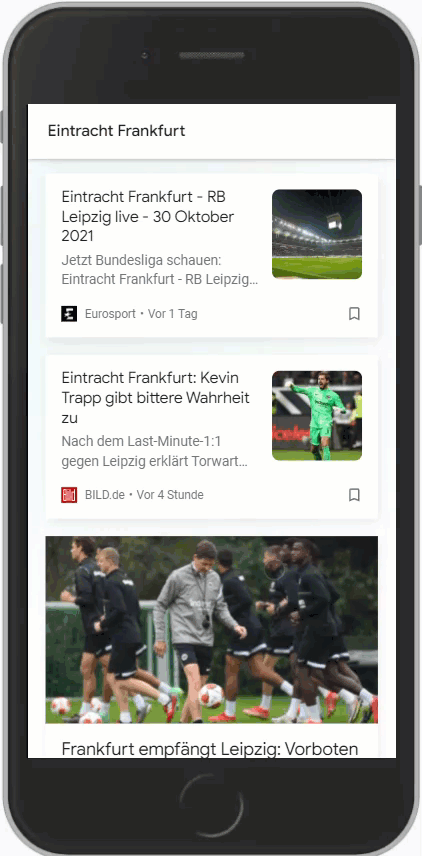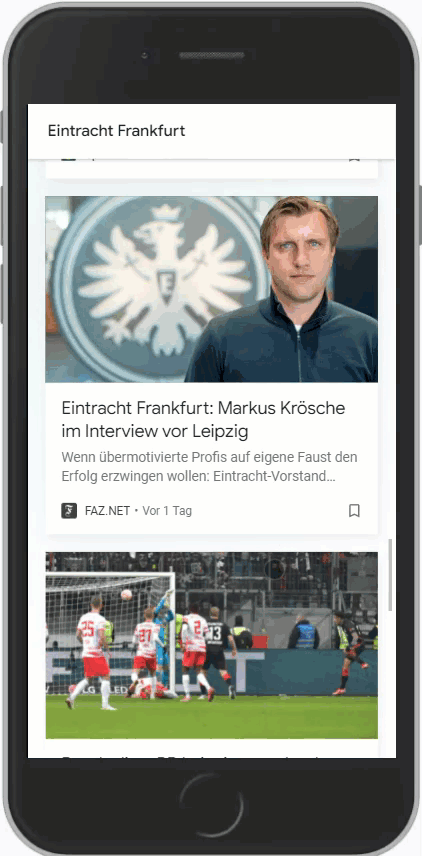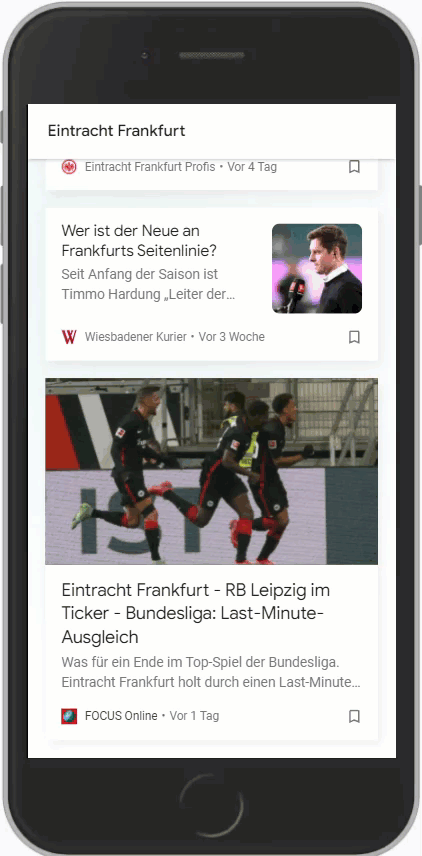
Es ist gut zu erkennen, dass zu Eintracht Frankfurt signifikant mehr Artikel im Feed sind als zur SGE. Google unterscheidet hier also.
Auch die NLP-API liefert beide Benennungen als Entität aus:

Dabei handelt es sich klar um zwei Benennungen einer und derselben Entität. Dieses Spiel lässt sich jetzt für jeden Fußballverein wiederholen.
Deshalb ist es für uns wichtig die für Google dominierende Benennung zu verwenden, um sicherzustellen, dass eine korrekte Zuordnung erfolgt. Ansonsten ist diese schlicht nicht sichergestellt was zu lasten unserer Ausspielung in Discover gehen kann.
Suchanfragen sind aber keine Entitäten
Der geneigte Leser wird jetzt zu Recht anmerken, dass Suchanfragen keine Entitäten sind. Wir nutzen den Parameter q aber gerne für ad-hoc Prüfungen. Es geht einfach schnell. Natürlich kann man auch gezielt Entitäten abfragen. Hierzu nutzt man dann folgende URL:
Hierbei gilt dann
- q als Parameter wird leer gelassen
- kgmid= hier wird die ID der Entität erfasst
In diesem Fall ist es die ID von Eintracht Frankfurt. Nur um im Thema zu bleiben. Die ID findet ihr einfach, indem ihr Google Trends bemüht.
Ihr gebt den gewünschten Suchbegriff ein und wählt im DropDown den gewünschten Eintrag, der NICHT Suchbegriff ist:

Nach der Auswahl kommt Ihr zu folgender URL: https://trends.google.de/trends/explore?q=%2Fm%2F03jb2n&geo=DE. Der hier rot markierte Wert für den Parameter q übernehmt Ihr dann in die oben angegebene URL als Wert für den Parameter kgmid.
Aber aufpassen, es gibt nicht für alles sinnvolle Entitäten. Für Rezept schlägt Google Trends nur Kochrezept vor. Womit man folgenden Feed erhält:
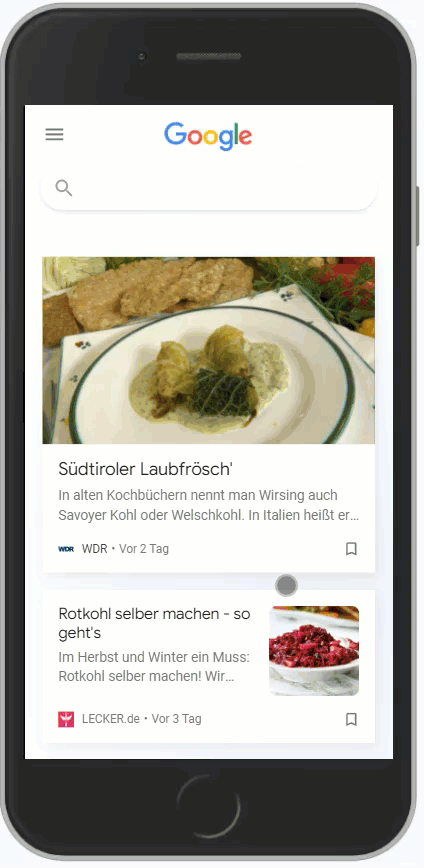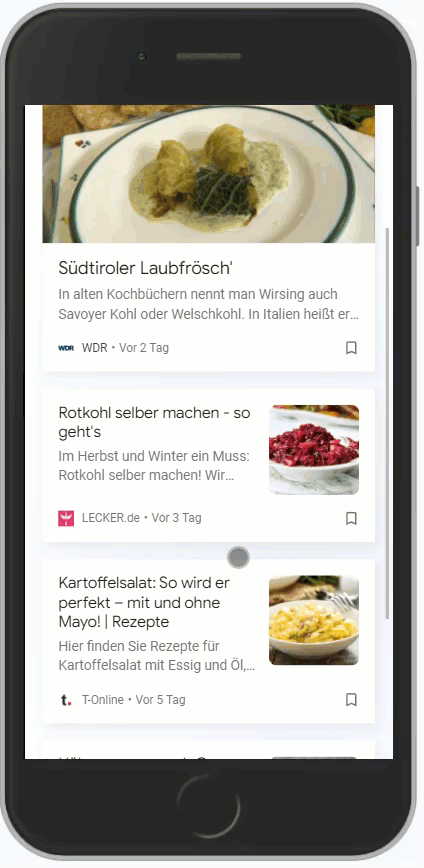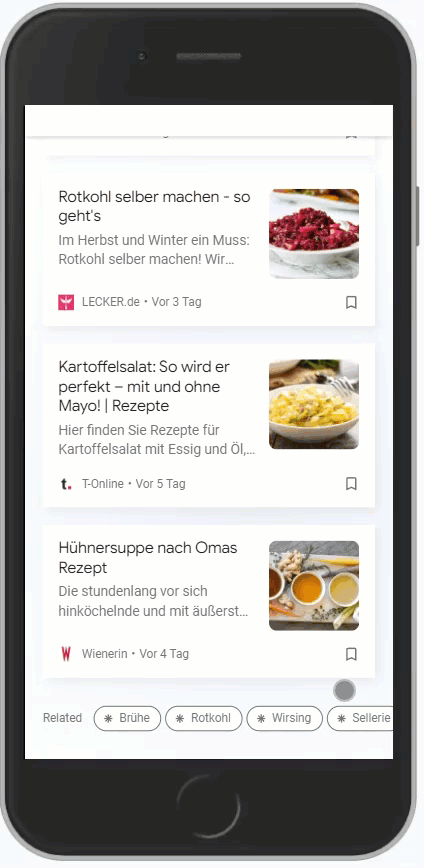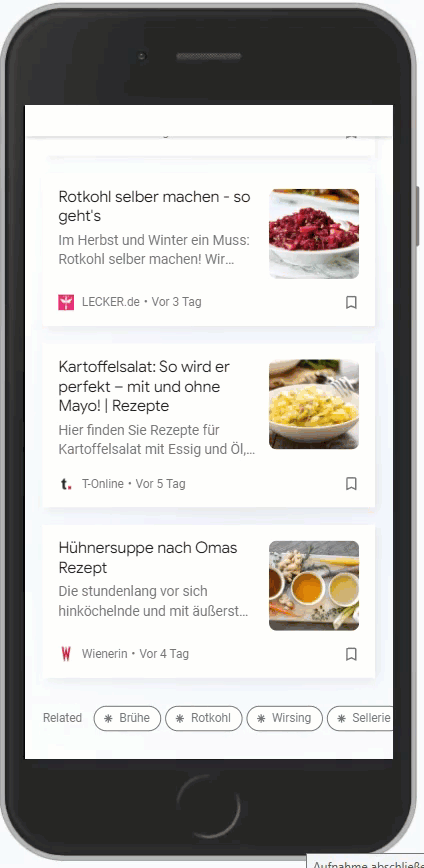
Dieser ist jetzt überschaubar. Eine Suche mit q=rezept liefert hier mehr Ergebnisse, weil es natürlich nicht nur Kochrezepte gibt:

Spannend an beiden Feeds sind die genutzten Formulierungen. Wenn man die eher sachlich und emotionsbefreiten Titel mal außer Acht lässt.
Formulierungen wie
- Selbst machen, so geht es
- So wird XYZ perfekt
- Omas Rezept
kann man gerne als Klicktreiber selbst ausprobieren. Ein Vergleich mit der Konkurrenz hinsichtlich der Formulierungen kann hilfreich sein, um die eigene Leistung in Discover zu steigern.
Aber auch die Verwendung weiterer Entitäten kann sinnvoll sein, um die eigene Reichweite zu steigern:

Hier kann sowohl Rezept als auch Halloween als Interesse getriggert werden. Im Erfolgsfall sehen wir in der Regel mehr Impressions bei allerdings sinkender CTR. Der Streuverlust ist einfach höher.
Dennoch sollte man solche Taktiken durchaus versuchen. Ein Vergleich mit der durchschnittlichen CTR über alle Storys zeigt im Nachgang, ob das Ergebnis zu vertreten ist.
Ich denke, das Vorgehen ist so weit klar. Jetzt liegt es an euch. Seid kreativ, lernt von den Ideen und Marktbegleitern und natürlich Happy optimizing!
DISCLAIMER
Die so abgefragten Feeds zu Suchbegriffen oder Entitäten sieht in dieser Form kein Nutzer von Discover. Jeder Nutzer hat eine Vielzahl von Interessen. Keiner hat also einen monothematischen Feed. Auch haben wir keine Erkenntnisse – mangels bisher durchgeführter Untersuchung – darüber, dass eine Positionierung weiter oben im abgefragten Feed zu mehr Impressions in Discover führt.

Jens Fauldrath
Geschäftsführender Gesellschafter
Ich habe von 2006 bis 2012 das SEO-Team für t-online.de aufgebaut. Dabei war es essenziell, Redaktion, Produktmanagement und IT gleichermaßen zu berücksichtigen und in den Veränderungsprozess einzubinden. Dieses haben wir erreicht, indem wir die vorhandenen Prozesse erhoben und SEO möglichst aufwandneutral in diese integriert haben




2 Kommentare:
Hallo.
Danke für den Tipp, aber er scheint nicht mehr zu funktionieren. Wenn ich die URL wie von Dir beschrieben nach der Umstellung auf Mobile in die Suchleiste des Browsers eingebe, dann findet ein Redirect statt und es wir eher ein normales Suchergebnis angezeigt, aber kein simulierter Discover Feed.
Kannst Du das bestätigen?
Danke und Grüße
Roland
Hallo Roland,
ich kann Deinen Fehler leider nicht reproduzieren. Bei mir funktioniert es noch wie beschrieben. Melde Dich gerne bei uns, dann können wir uU zusammen drauf schauen.
LG, Jens