
Der großartige Stefan Fischerländer hat auf der SMX einen tollen Vortrag zum Thema Weiterleitungsmanagement für SEOs gehalten. Zunächst hatte er die Befürchtung, wie er mit diesem Thema eine Stunde füllen soll. Nach kurzer Zeit ist ihm aber bewusst geworden, wie umfangreich das Thema ist und so konnten die Zuhörer 60 Minuten gebannt zuhören, welche Facetten es zu beachten gibt, was die Status Codes technisch überhaupt bedeuten und wie ein vernünftiges Weiterleitungsmanagement aussieht. Entsprechend möchte ich an dieser Stelle gar nicht auf das Warum eingehen, sondern vielmehr an seinen Vortrag anschließen und das Wie beleuchten.
Um es nicht ganz aus den Augen zu verlieren, hier aber dennoch ein sehr kondensiertes tl;dr zum Weiterleitungsmanagement an sich:
Das Weiterleitungsmanagement – sprich: das Einrichten neuer und die Pflege bestehender Weiterleitungen – ist ein signifikanter Aspekt der SEO-Arbeit. Es stellt sicher, dass nicht mehr erreichbare Seiten zielgerichtet auf andere, thematisch-relevante Seiten weitergeleitet werden können. Dadurch wird sichergestellt, dass Nutzer nicht in “Sackgassen” stecken bleiben und bestehende Rankings ggf. auf äquivalente Seiten übertragen werden.
Nun ist es dabei natürlich wichtig, dass derartige Weiterleitungen ad hoc im System eingepflegt werden können, ohne bspw. einen Umweg über die IT gehen oder ein Release abwarten zu müssen. Hierfür bietet es sich an, dass es einen zentralen Editor gibt, der alle Weiterleitungen übersichtlich darstellt. Darum soll es in diesem Beitrag gehen.
Was muss ein solcher Redirect-Editor an Funktionen bereitstellen?
- Manuelles Anlegen von Weiterleitungen
- Importieren von Weiterleitungs-Listen
- Automatisches Weiterleiten von geänderten oder gelöschten URLs
- Darstellung aller eingepflegten Redirects mit der Möglichkeit zur Filterung, Sortierung und Editierung dieser Weiterleitungen
- Überwachung der Redirect-Ziele, ob diese weiterhin erreichbar sind oder mittlerweile selbst weiterleiten resp. gelöscht wurden.
- Export der gesetzten Weiterleitungen zur Weiterverarbeitung in anderen Programmen o.ä.
Nun denn, wie haben wir uns einen solchen Redirect-Editor vorzustellen? Grundsätzlich fordern wir ihn als eigenständiges Modul im CMS des Kunden an, damit dieser an einer zentralen Stelle seine Weiterleitungen setzen und pflegen kann. Wichtig ist dabei das graphische User-Interface, dass die Arbeit so angenehm wie möglich machen sollte. Denn sind wir ehrlich, die Definition von Weiterleitung macht jetzt nicht gerade Spaß. Und wenn ich Redirects in Excels dokumentieren und diese womöglich händisch in der htaccess pflegen muss, kann ein jeder nachvollziehen, warum dieses Thema mitunter stiefmütterlich gehandhabt wird.
Genereller Aufbau eines Redirect-Editors
Der Editor könnte wie folgt aufgebaut sein.
Falls euch das Layout bekannt vorkommt, so ist das kein Wunder, denn ich habe mich hier schamlos beim Editor des WordPress-Plugins Yoast bedient. Ich habe es allerdings um Funktionalitäten ergänzt, die sich in der täglichen SEO-Arbeit mit großen Websites herauskristallisiert haben.
Komponenten eines Redirect-Editors
Der Redirect-Editor besteht aus fünf Komponenten, die verschiedene Aufgaben übernehmen. Sie dienen konkret dem Anlegen, Betrachten und Exportieren von Weiterleitungen. Diese Komponenten schauen wir uns nun nachfolgend im Detail an. Mitunter gehen wir dabei sehr in die Tiefe, denn wie bereits anfangs geschrieben, kommt das Thema vermeintlich einfach daher – werden allerdings einzelne Fälle betrachtet, muss man sehr viel dabei bedenken und entscheiden. Entsprechend optional muss der Editor auch sein, um sich bei jedem Fall für die eine oder andere Variante zu entscheiden. Aber legen wir los.
Manuelle Redirects im anlegen
Das zentrale Feature des Editors ist es – welch Überraschung –, Weiterleitungen anzulegen. Dabei muss aber zwischen dem manuellen Anlegen von Redirects – also ich trage eine einzelne URL ein und spezifiziere ein konkretes Weiterleitungs-Ziel für diese URL –, dem Import von Redirect-Listen und dem automatischen Weiterleiten von geänderten oder gelöschten URLs differenziert werden.
Der folgende Screenshot zeigt das Modul für das Anlegen von einzelnen Weiterleitungen. Die gelben Notizenzettel stellen die möglichen Ausprägungen der Dropdowns dar.
Wie im Screenshot zu erkennen, bietet das Modul dem Nutzer verschiedene Freitext- und Auswahlfelder, mit den folgenden Funktionalitäten:
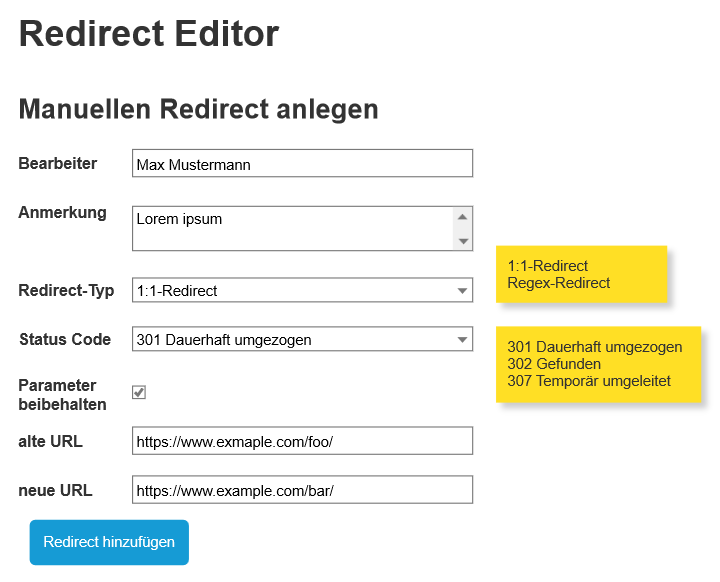
- Bearbeiter (Freitext)
Hier kann der jeweilige Bearbeiter seinen Namen eintragen. Der eingetragene Name erscheint in der Übersichtstabelle der Redirects in der Spalte Bearbeiter. Übersichtstabelle meint die Tabelle, die im ersten Screenshot zu sehen und alle Redirects übersichtlich in einer Tabelle darstellt. Ergibt irgendwie Sinn, oder? Konkreter wird’s dann im Abschnitt Übersichtstabelle. Die Angabe des Namens dient a) dazu, den Verantwortlichen eines Redirects ermitteln zu können und b) – bspw. mittels der Suche – nur solche Redirects anzuzeigen, die man selbst angelegt hat. - Anmerkung (Freitext)
Hier kann eine kurze Information eingetragen werden, die den Redirect beschreibt. Die Anmerkung erscheint in der Übersichtstabelle in der Spalte Anmerkung. Die Anmerkung dient dazu, Redirects schnell suchen zu können – bspw., wenn für Kampagnen-Shortlinks standardisierte Anmerkungen in der Form “Facebook – Campaign – Sonderangebote” verwendet werden. Oder um allgemein den Grund für einen Redirect zu beschreiben. - Redirect-Typ (Auswahl: 1:1-Redirect (default), Regex-Redirect)
Hier muss der Bearbeiter eine Auswahl treffen, ob die alte URL exakt oder musterbasiert gematcht werden soll. Die Differenzierung ist nötig, da eine exakte zu matchende URL durchaus Zeichen enthalten kann, die in Regex eine gesonderte Bedeutung haben.
Beispiel: Die URLhttps://example.com/foo?q=lorem+ipsumenthält die Zeichen?und+, die in Regex Meta-Zeichen mit eigener Bedeutung darstellen.
Der ausgewählte Typ wird in der Übersichtstabelle in der Spalte Typ dargestellt. - Status Code (Auswahl: 301 Dauerhaft umgezogen (default), 302 Gefunden, 307 Temporär umgeleitet)
Hier kann der Bearbeiter den Status Code des Redirects definieren. Standard ist 301 Dauerhaft umgezogen. Die beiden anderen Status Codes adressieren Edge-Cases, die sehr selten benötigt werden, aber dennoch mit dem Redirect-Editor umsetzbar sein sollten. Der Status Code des Redirects wird in der Tabelle in der Spalte Status Code Redirect aufgeführt. - Parameter beibehalten (Checkbox; ja (default), nein)
Hier kann der Bearbeiter mittels Checkbox bestimmten, ob Parameter, die an eine weiterzuleitenden URL angehängt sind, automatisch auf das Weiterleitungsziel übertragen werden sollen. Der Umgang mit parametrisierten URLs kann schnell komplex und kompliziert werden. Für eine exemplarische Beschreibung der möglichen Implikationen siehe Umgang mit parametrisierten URLs. - alte URL (Freitext)
Die URL oder das URL-Pattern, das weitergeleitet werden soll. Zur detaillierten Spezifikation, welche URLs hier erlaubt sind, siehe Spezifikation der eintragbaren URLs. - neue URL (Freitext)
Die URL, auf die die Weiterleitung erfolgen soll. Zur detaillierten Spezifikation, welche URLs hier erlaubt sind, siehe Spezifikation der eintragbaren URLs.
Da ihr einen derartigen Redirect-Editor mit Sicherheit nicht Out-of-the-Box bekommen werdet, sondern ihn bei eurer Technik anfordern müsstet, werde ich euch zu jedem Modul auch noch die Details geben, wie mit der Eingabe des Nutzers zu verfahren ist. Ansonsten kommt ihr nämlich sehr schnell in unzählige Abstimmungsrunden mit eurer IT, weil „das ja nie in der Form so angefordert wurde“.
Verhalten des Redirect-Editors beim manuellen Eintragen eines Redirects
Wird ein manueller Redirect über den Button Redirect hinzufügen eingetragen, sind folgende Prüfpunkte abzuarbeiten, bevor der Redirect ins System übernommen wird.
- Alle Felder sind befüllt.
- Die alte URL ist regelkonform (s. Spezifikation der eintragbaren URLs)
- Die neue URL ist regelkonform (s. Spezifikation der eintragbaren URLs)
Ist eine der Bedingungen nicht erfüllt, bricht die Eintragung ab und der Nutzer erhält einen spezifischen und verständlichen Hinweis darauf, welches Prüfkriterium verletzt wurde. Noch mal, der Nutzer erhält einen Hinweis, mit dem er etwas anfangen kann. Häufig wird dieser Redirect-Editor nicht nur von SEOs verwendet, sondern auch von Redakteuren oder Produkt-Managern. Letztere sind wahrscheinlich schon genervt, dass sie überhaupt diese „SEO-Weiterleitungen“ bedenken müssen. Entsprechend müssen die Hürden beim Anlegen eines Redirects so gering wie möglich sein. Und nichtssagende Fehlermeldungen sind einer der maßgeblichen Gründe, ein Tool nach dem ersten Versuch nie wieder zu verwenden und fortan den SEO zu nerven, die Redirects einzutragen.
Sind alle Bedingungen erfüllt, wird der Redirect ins System übernommen und unmittelbar in der Übersichtstabelle dargestellt. Die folgenden Spaltenwerte – die nicht durch den Bearbeiter manuell definiert wurden – werden dabei automatisch befüllt.
- ID
Fortlaufende, einzigartige Identifikationsnummer. Warum? Weil es irgendwann Situationen gibt, in denen es einfacher ist, eine Nummer zu haben, mit der sich ein Redirect zweifelsfrei identifizieren lässt. Und sei es nur, um die Frage eines Kollegen „Von welchem Redirect sprechen wir jetzt gerade?“ schneller und eindeutig beantworten zu können. - Erstellt
Das aktuelle Datum im FormatYYYY-MM-DD. Und nein,MM.YYYYoderMM/DD/YYYYoder was auch immer, sind keine Option. Sortiert mal nach einem solchen Datumsformat und ihr wisst warum. - Status Code neue URL
Der Status Code des Weiterleitungsziel zum Zeitpunkt der Eintragung des Redirects. Als Nutzer will ich den Status Code des Ziels direkt sehen, damit ich nicht fälschlich auf eine 404-Seite oder einen Redirect weiterleite. Das ist allerdings etwas tricky, denn häufig kennt das System diesen Status Code zum Zeitpunkt der Eintragung gar nicht – sprich: beim Eintragen muss zunächst einmal ein GET-Request ausgeführt werden, um diesen zu ermitteln. Sollte das das Eintragen des Redirects deutlich verzögern – wie gesagt, oberste Prämisse des Redirect-Editors ist die Fluptizität, also das reibungslose Arbeiten damit – kann die Abfrage auch erst später erfolgen. Siehe dazu Regelmäßige Abfrage der Status Codes und Titles der Weiterleitungsziele. Notfalls kann der Nutzer die Ziel-URL immer noch selbst im Browser aufrufen, um den Status Code manuell zu checken. - Title
Der<title>des Weiterleitungsziels zum Zeitpunkt der Eintragung des Redirects. Auch hier gilt, dass diese Information ggf. nicht zum Zeitpunkt der Eintragung unmittelbar zur Verfügung steht – dann muss sie zu einem späteren Zeitpunkt nachgetragen werden. Wichtig ist diese Information aber auf jeden Fall, denn Nutzer denken häufig nicht unbedingt in URLs – insbesondere, wenn diese nicht sprechend sind – sondern orientieren sich am Title einer Seite, um den Inhalt schnell zu erfassen und das Weiterleitungsziel auf Relevanz zu prüfen. Beim Zeitpunkt der Eintragung wird der Nutzer die Ziel-Seite eh manuell identifizieren. Später, beim Verwenden der Übersichtstabelle, ist der Title aber unabdingbar, um sich einen schnellen Überblick über den Inhalt zu verschaffen.
Redirects in den Redirect-Editor importieren

Häufig – insbesondere im Zuge von Relaunchs – muss eine Liste von Weiterleitungen eingepflegt werden. Um den manuellen Aufwand gering zu halten, kann hier eine CSV in definiertem Format hochgeladen werden. Das vorgegebene Format ist wie folgt.[Bearbeiter];[Anmerkung];[alte URL];[neu URL]...
Ein Beispiel:Erika Musterfrau;Relaunch Bulk Redirect 00001;https://example.de/;https://example.com/...
Da es sich hier um eine automatisch zu verarbeitende CSV handelt, ist es wichtig, dass der Ersteller der Liste einige Konventionen beachtet:
- Die CSV enthält keine Überschriften-Zeile. Das ist robuster als zu sagen, dass die Datei immer eine Überschriften-Zeile besitzen muss, diese dann beim Import zu verwerfen, um dann Gefahr zu laufen, dass Nutzer doch keine Überschriften verwenden und dadurch Redirects verloren gehen.
- Als Trennzeichen der Spalten wird ein Semikolon ; verwendet. Da viele Nutzer die Listen in Excel erstellen und dieses in Deutschland CSV mit Semikolon exportiert, dürfte das die sichere Variante sein. Ist die Situation anderes, sollte natürlich immer die am weitesten verbreitete Variante gewählt werden.
- Da das Semikolon als Trennzeichen verwendet wird, darf es in keinem der Felder als Zeichen verwendet werden – bspw. darf der Bearbeiter nicht als
Erika Mustermann; Max Mustermannangegeben werden. Es kann in sehr seltenen Fällen vorkommen, dass URLs Semikolons enthalten. Diese dürfen somit nicht importiert werden, sondern müssen manuell eingetragen werden. - Es können nur 1:1-Redirects importiert werden. Regex-Redirects sind manuell einzutragen. Daher fehlt das Feld Redirect-Typ. Dies hat den Grund, dass Regex-Redirects sehr bewusst eingesetzt werden sollten. Daher wird eine manuelle Eingabe dadurch erzwungen, dass sie im Import als 1:1-Redirects und nicht als Regex-Redirects evaluiert werden. Regex-Redirects würden somit zwar ins System übernommen werden, allerdings nicht funktionieren.
- Redirects können nur mit dem Status Code 301 importiert werden. Daher fehlt das Feld Status Code. Auch dies soll sicherstellen, dass Redirects mit dem Status Code 302 oder 307 mit Bedacht definiert werden, indem sie manuell angelegt werden müssen.
- Die zugrundeliegende Einstellung ist derart, dass Query-Parameter automatisch von der weiterzuleitenden URL mitgenommen und an das Weiterleitungsziel angehängt werden.
Der Nutzer wird somit bewusst eingeschränkt, um den Import so reibungslos wie möglich zu gestalten. Ich kann als Nutzer tausende von URLs hochladen und damit enorm viel Zeit sparen – muss mich dafür aber auch an ein paar Regeln halten.
Aller Einschränkungen zum Trotz kann der Import aber dennoch missgeformt sein. Daher muss er entsprechend der folgenden Kriterien evaluiert werden
Verhalten des Editors beim Importieren von Redirects
Wurde eine Datei ausgewählt, prüft das System, ob die Datei dem vorgegeben Format entspricht. Sollte dies nicht der Fall sein, bricht der Import ab und der Nutzer erhält eine Fehlermeldung, die ihn auf das inkorrekte Format hinweist. Inkorrekte Formate können bspw. bedingt sein durch falsche Trennzeichen (Kommata, Tabs etc. statt Semikolons) oder zu wenige / zu viele Spalten.
Wird die Datei akzeptiert, gibt die nebenstehende Fortschrittsanzeige an, wie viele der Redirects verarbeitet wurden. Ist der Import abgeschlossen, sind folgende Prüfpunkte abzuarbeiten, bevor die Redirects ins System übernommen werden.
- Alle Felder sind befüllt.
Es ist somit nicht zulässig, eine Zeile wie die folgende zu importieren;;https://example.de/;https://example.com. Erfahrungsgemäß ist gerade beim Bulk-Import von Redirects sicherzustellen, dass der Verantwortliche ermittelt werden kann und in welchem Kontext die Redirects eingepflegt wurden. Daher sollten auch beim Import die Pflichtfelder – wie bei der manuellen Erstellung eines Redirects – gelten. - Die alte URL ist regelkonform (s. Spezifikation der eintragbaren URLs)
- Die neue URL ist regelkonform (s. Spezifikation der eintragbaren URLs)
Ist eine der Bedingungen nicht erfüllt, sind unterschiedliche Verhalten des Redirect-Editors denkbar.
Option 1: Bearbeitung der zurückgewiesenen Redirects direkt im Redirect-Editor
Alle gültigen Redirects werden importiert und in das System eingetragen. Alle Zeilen – sprich: Redirect-Definitionen – die ein Prüfkriterium verletzt haben, werden nicht in das System eingetragen. Am Ende des Importvorgangs erhält der Nutzer eine tabellarische Übersicht aller Redirects sowie die jeweilige Beanstandung. Die Tabelle kann wie folgt aufgebaut sein.

Der Nutzer hat dann die Möglichkeit, die zurückgewiesenen Redirects nacheinander manuell zu bearbeiten. (Zur detaillierten Beschreibung der Funktionalität der Tabelle s. Übersichtstabelle). Wird durch die Bearbeitung der Verstoß behoben, wird der Wert in der Spalte Import-Fehler zu Import-Fehler behoben geändert. Entsteht durch die Bearbeitung ein anderer Verstoß, wird dieser als Wert in die Spalte Import-Fehler geschrieben. Lässt sich ein Fehler nicht beheben, kann der Redirect über löschen vom Import ausgenommen werden.
Der Nutzer hat über den unter der Tabelle befindlichen Button Redirects erneut importieren jederzeit die Möglichkeit, alle Redirects, die valide sind, erneut zu importieren. Die validen, erneut importierten Redirects werden ins System eingetragen und aus der Übersichtstabelle entfernt.
Option 2: Abbruch des gesamten Imports
Erfahrungsgemäß ist der Implementierungsaufwand für Option 1 hoch. Auch wenn Option 1 anzustreben ist, da es die Arbeit signifikant erleichtert, kann die nachfolgend beschriebene Option eine Alternative darstellen.
Tritt bei der Evaluation der importierten Liste ein Verstoß gegen eines der Prüfkriterien auf, bricht der gesamte Import ab. Der Nutzer erhält eine Fehlermeldung mit dem Hinweis darauf, welches Kriterium verletzt wurde und in welcher Zeile der CSV dies aufgetreten ist. Der Nutzer muss dann in der CSV selbst den Fehler beheben und die CSV erneut importieren.
Keine Option ist es, Redirects, die eines der Prüfkriterium verletzten, stillschweigend – also ohne Feedback an den Nutzer – zu übergehen.
Redirects aus dem Redirect-Editor exportieren
Es ist nie verkehrt, alle Redirects exportieren zu können – bspw. um sie als Input für einen Crawler zu verwenden.
Über den Button Export starten können alle eingetragenen Redirects exportiert werden. Die CSV-Datei ist wie folgt aufgebaut und weist eine Überschriften-Zeile auf.
"ID";"Erstellt";"Bearbeiter";"Anmerkung";"Typ";"Status Code Redirect";"alte URL";"neue URL";"Status Code neue URL";"Title""[ID]";"[Erstellt]";"[Bearbeiter]";"[Anmerkung]";"[Typ]";"[Status Code Redirect]";"[alte URL]";"[neue URL]";"[Status Code neue URL]";"[Title]"...
Es kann vorkommen, dass Nutzer beim manuellen Anlegen von Redirects Semikolons verwenden. Da diese als Trennzeichen in der Export-CSV verwendet werden, werden alle Zellenwerte standardmäßig durch Anführungszeichen “ qualifiziert. Treten innerhalb der Zellenwerte ebenfalls Anführungszeichen auf, sind diese automatisch zu escapen („Das ist eine \"Anmerkung\" mit Anführungszeichen„).
Übersichtstabelle
Die Übersichtstabelle dient zur Darstellung aller eingepflegten Redirects. Sie muss es dem Benutzer ermöglichen, die Eigenschaften eines Redirects schnell erfassen und ggf. bearbeiten zu können.

Grundlegendes
- Sortierung
- Die Tabelle ist initial absteigend nach dem Erstellungsdatum sortiert (aktuellster Redirect am Anfang der Tabelle).
- Der Nutzer kann durch das Klicken der Spaltenüberschriften jede Spalte auf- / absteigend sortieren.
- Anzahl der Redirects und Pagination
- Die Tabelle listet initial 25 Redirects. Sind mehr Redirects vorhanden, wird die Liste paginiert. Dies dient dazu, die Ladezeit der Ansicht zu verkürzen. Sollten mehr Redirects dargestellt werden können, sind die 25 Redirects natürlich kein in Stein gemeißeltes Limit.
- Der Nutzer kann über ein Dropdown mehr oder weniger Redirects je Seite anzeigen. Je nach Performance des Systems empfehlen sich Schritte wie 5, 10, 25, 50, 100.
- Der Nutzer kann über eine Pagination die einzelnen Seiten der Tabelle aufrufen.
- Darstellung der Zellenwerte
- Alle Zellenwerte – insbesondere alte URL und neue URL – werden gänzlich, also in nicht abgeschnittener Form, dargestellt. Um dies sicherzustellen, kann der Zelleninhalt umbrechen. Die Spaltenbreite ist für den Nutzer anpassbar wie man es bspw. aus Excel kennt.
Spalten
Die Tabelle besteht aus folgenden Spalten:
- Checkbox-Spalte
Diese Spalte enthält Checkboxen, anhand derer mehrere Redirects auf einmal ausgewählt werden können, um sie bspw. zu löschen (für die detaillierte Beschreibung der Mehrfachauswahl s. Mehrfachauswahl). - ID (automatisch generiert)
Die fortlaufende, einzigartige, automatisch beim Anlegen eines Redirects generierte Identifikationsnummer des jeweiligen Redirects. - Erstellt (automatisch generiert)
Das automatisch beim Anlegen eines Redirects eingetragene Erstellungsdatum im FormatYYYY-MM-DD. - Bearbeiter
Der beim manuellen Erstellen / Importieren des Redirects durch den Nutzer angegebene Bearbeiter. - Anmerkung
Die beim manuellen Erstellen / Importieren des Redirects durch den Nutzer angegebene Anmerkung. - Typ (teilweise automatisch generiert)
Entweder der beim manuellen Erstellen durch den Nutzer angegebene Typ des Redirects mit den möglichen Ausprägungen 1:1 und Regex.
Oder die vom System automatisch gesetzte Ausprägung automatisch, wenn die URL einer Seite im System geändert wurde. Zur genauen Beschreibung des systemischen Verhaltens bei automatischen Redirects kommen wir im Abschnitt Automatische Redirects.
Oder die vom System automatisch gesetzte Ausprägung importiert, wenn ein Redirect mittels Bulk-Imports importiert wurde. - Status Code Redirect (teilweise automatisch generiert)
Entweder der beim manuellen Erstellen durch den Nutzer angegebene Status Code des Redirects mit den möglichen Ausprägungen 301, 302 oder 307.
Oder der vom System automatisch vergebenen Status Code 301, wenn eine URL im System geändert oder ein Redirect importiert wurde. - alte URL
Die weiterzuleitende URL. - neue URL
Das Weiterleitungsziel. - Status Code neue URL
Der aktuelle Status Code der neuen URL, sprich: des Weiterleitungsziels (für die detaillierte Beschreibung der Ermittlung des Status Codes s. Regelmäßige Abfrage der Status Codes und Titles der Weiterleitungsziele). Die Status Codes 3xx und 4xx, die anzeigen, dass die definierte Ziel-URL nicht (unmittelbar) erreichbar ist, werden farblich hervorgehoben. 3xx in Orange, 4xx in Rot. - Title
Der aktuelle Browser-Title (<title>) der neuen URL (für die detaillierte Beschreibung der Ermittlung des Titles s. Regelmäßige Abfrage der Status Codes und Titles der Weiterleitungsziele).
Bearbeiten
Buttons zum Bearbeiten oder Löschen des nebenstehenden Redirects. Beim Klick auf den Button werden die Spaltenzellen des jeweiligen Redirects direkt in der Tabelle in Form von Dropdowns und Freitextfeldern editierbar. Die Optionen in der Spalte Bearbeiten ändern sich zu aktualisieren, um die Änderung am Redirect zu übernehmen, und abbrechen, um die Bearbeitung abzubrechen.
Es können alle Spalten editiert werden ausgenommen der Spalten ID und Erstellt. Der Wert der Spalte Erstellt aktualisiert sich nach dem Speichern der Bearbeitung automatisch entsprechend des aktuellen Datums.
Mehrfachauswahl

Wie zuvor bereits erwähnt, weist die Übersichtstabelle in der ersten Spalte Checkboxen auf, mit denen sich eine oder mehrere Redirects markieren lassen. Die Checkbox in der Tabellenüberschrift dient zur Aus- / Abwahl aller Redirects der aktuellen Pagination (befindet sich der Nutzer also auf Seite 1 der Tabelle und wählt die Checkbox in der Tabellenüberschrift aus, werden nur die Redirects der Seite 1 und nicht der Seiten 2 – n markiert).
Wurden ein oder mehrere Redirects markiert, kann der Nutzer über das oberhalb der Tabelle befindliche Dropdown eine Aktion durchführen:
- Löschen
Die markierten Redirects werden gelöscht. Bevor die Löschung erfolgt, muss der Nutzer mittels eines Dialogs dem Löschen zustimmen. Wurden die Redirects aus dem System gelöscht, aktualisiert sich die Tabellenansicht von selbst. - Status Code & Title prüfen
Der Status Code und Browser-Title der neuen URL der markierten Redirects wird ad hoc abgefragt. Die Tabellenansicht aktualisiert sich von selbst nach der Abfrage. Idealerweise gibt es eine Fortschrittsanzeige, wie viele der Redirects bereits verarbeitet wurden, um dem Nutzer ein visuelles Feedback zu geben – insbesondere, wenn für viele Redirects die Abfrage erfolgt. - Exportieren
Die markierten Redirects werden als CSV exportiert.
Durch das Betätigen des Ausführen-Buttons wird die ausgewählte Aktion durchgeführt.
Suche

Die Suche dient dazu, die Übersichtstabelle ad hoc filtern zu können, um somit nur die gewünschten Redirects betrachten zu können. Ohne eine vollwertige Such- und Filterfunktionalität ist die effiziente Arbeit mit einem Redirect-Editor kaum möglich. Denn erfahrungsgemäß müssen bestehende Redirects immer mal wieder angefasst werden. Um nur einen Anwendungsfall zu nennen: Ich schaue mir wöchentlich den Status Code der Zielseiten an, ob diese weiterhin erreichbar sind. Dazu filtere ich die Spalte auf den Status Code 404 und arbeite dann Redirect für Redirect ab. Ohne die Filtermöglichkeiten artet allein so etwas sehr schnell in Export-Aufbereitungs-Import-Kaskaden aus.
Die Suche besteht aus drei Dropdowns und einem Freitextfeld.
- Ein- / Ausschließen-Dropdown
Das Dropdown bietet die Optionen Einschließen (Default) und Ausschließen zur Auswahl. Der Nutzer kann hiermit definieren, ob bei der Anzeige der Suchergebnisse, die durch das nachfolgenden Such-Statement getroffenen oder nicht getroffenen Zeilen in der Übersichtstabelle angezeigt werden sollen. Ausschließen ist somit die Negation des Such-Statements – anders gesagt: ein NOT-Operator. - Zielspalte-Dropdown
Das Dropdown bietet die Möglichkeit das nachfolgende Such-Statement auf alle Spalten (Überall; Default) oder eine bestimmte Spalte anzuwenden. Alle Spalten können adressiert werden (ausgenommen sind natürlich die Checkbox- und Bearbeiten-Spalten). - Such-Operator-Dropdown
Der Suchoperator determiniert, in welcher Form der im Freitextfeld eingegebene String evaluiert werden soll.- Enthält (Default)
Der Such-String ist buchstäblich in einer der Spalten (Zielfeld: Überall) oder der der explizit angegeben Zielspalte enthalten.
Bsp.:/foo/trifft sowohl die alte URLhttps://exp.com/foo/bar/als auch die AnmerkungWeiterleitung des Verzeichnisses /foo/. - Entspricht genau
Der Suchstring ist buchstäblich identisch mit dem Wert einer Zielspalte.
Bsp.:https://exp.com/foo/trifft die neue URLhttps://exp.com/foo/aber nichthttps://exp.com/foo/bar/. - Regex
Der Wert einer Zielspalte enthält das angegeben Regex-Pattern.
Bsp.: Das Pattern/fo.*?/triffthttps://exp.com/foobar/. Es wird also nur geprüft, ob das angegeben Pattern im Wert enthalten ist. Das Pattern muss nicht den gesamten Wert treffen. Es ist somit nicht nötig, das Pattern als.*/fo.*?/.*zu definieren, umhttps://exp.com/foobar/zu treffen. - Beginnt mit
Der Wert einer Zielspalte beginnt mit dem angegeben Such-String. - Endet mit
Der Wert einer Zielspalte endet mit dem angegeben Such-String.
- Enthält (Default)
- Freitextfeld
Das Freitextfeld nimmt den gewünschten Such-String resp. das gewünschte Such-Pattern entgegen.
Ein Klick auf den Button Suchen führt die definierte Suche aus und aktualisiert die untenstehende Tabelle entsprechend der Ergebnisse.
Fazit: Redirect-Editor
So wie das Weiterleitungsmanagement nicht „mal eben“ gemacht ist, ist auch die Anforderung eines Redirect-Editors, mit dem ich die Weiterleitungen überhaupt erst umsetzen kann, nicht „mal eben“ definiert. Ich hoffe, ich konnte euch mit der obigen Beschreibung einen ersten Wurf an die Hand geben, um gemeinsam mit eurer IT in die Abstimmung zu gehen. Wie das in unserem Feld aber immer so ist, gibt es nicht die eine Lösung. Einige der skizierten Funktionen werden für euch vllt. nicht sinnvoll sein oder sind in der Umsetzung derartig aufwendig, dass sie ignoriert werden müssen. Wie immer also: It depends.
Appendix: Technische Prämissen und Logiken
Als ich eingangs davon gesprochen habe, dass ich „nur“ den Editor beschreiben werden, habe ich natürlich gelogen. Der Editor muss von gewissen Prämissen ausgehen, auf die ich bereits ständig verwiesen habe und die im nachfolgenden, technischen Appendix im Detail beschrieben werden.
Redirect-Kaskade
Im Nachfolgenden gilt die Prämisse, dass es sich bei der vorliegenden Domain um https://www.example.com/ handelt.
URL-Normalisierung
Im Rahmen des Redirect-Managements – sprich: wie mit URLs verfahren wird, die nicht der Standard-Form entsprechen – gelten die folgenden Redirects als vorgelagert. Das heißt, eine nicht standardkonforme URL durchläuft die folgende Kaskade, bevor sie gegen die im Redirect-Editor definierten Weiterleitungen geprüft wird. Dadurch wird sichergestellt, dass die auf einen möglicherweise bestehenden Redirect zu prüfende URL in einer standardisierten Form vorliegt, die keine Unklarheiten zulässt. Die Reihenfolge der zu durchlaufenden Standardisierungsschritte ist die folgende:
- Protokoll
Alle URLs, die mithttpangefragt werden, werden aufhttpsvia301weitergeleitet.http://example.com/foö→https://example.com/foöhttp://example.com/foö?q=bar→https://example.com/foö?q=barhttp://example.com/foö#bar→https://example.com/foö#bar - Subdomain
URLs, die ohne Subdomain angefragt werden, werden auf diewww.weitergeleitet. Natürlich kann auch der umgekehrte Fall eintreten, wenn die nicht-www-Variante die Standard-Form ist. Zu bedenken ist der Umgang mit einer etwaig vorhandenen mobilen Subdomain (https://m.example.com/). An dieser Stelle wird davon ausgegangen, dass die www-Variante die bevorzuge Variante ist.https://example.com/foö→https://www.example.com/foöhttps://example.com/foö?q=bar→https://www.example.com/foö?q=barhttps://example.com/foö#bar→https://www.example.com/foö#bar - Umlaute, diakritische Zeichen und Sonderzeichen
Alle Umlaute sind aufzulösen, diakritische Zeichen auf ihre Grundform zu reduzieren und Sonderzeichen zu entfernen.https://www.example.com/foö→https://www.example.com/fooehttps://www.example.com/foö?q=bar→https://www.example.com/fooe?q=barhttps://www.example.com/foö#bar→https://www.example.com/fooe#bar - Trailing-Slash
URLs, die ohne Trailing-Slash angefragt werden, werden um diesen ergänzt. Natürlich kann auch hier der umgekehrte Fall eintreten, sodass evtl. vorhandene Trailing-Slashes zu entfernen sind.https://www.example.com/fooe→https://www.example.com/fooe/https://www.example.com/fooe?q=bar→https://www.example.com/fooe/?q=barhttps://www.example.com/fooe#bar→https://www.example.com/fooe/#bar
Durch die Normalisierung der URLs wird sichergestellt, dass innerhalb des Redirect-Editor keine Unklarheit darüber besteht, in welcher Form die weiterzuleitende URL einzutragen ist. Angenommen eine URL mit dem Pfad /foo/bar/ soll weitergeleitet werden. Der Nutzer trägt in den Redirect Editor nur die URL https://www.example.com/foo/bar/ ein. Er kann sich damit sicher sein, dass alle abweichenden Verlinkungen – bspw. http://example.com/foo/bar – ebenfalls durch den eingetragenen Redirect adressiert werden.
1:1- / n:1-Redirects
Nach den vorgelagerten Redirects, die die URL normalisieren, greifen Redirects, die im Redirect-Editor definiert werden.
Umschreibungen von URL-Bestandtteilen
Zum Schluss greifen Redirects, die spezifische Bestandteile von URLs umschreiben – ein klassisches Beispiel ist hier eine Verzeichnisänderung in der Form: https://www.example.com/altes-verzeichnis/foo/ → https://www.example.com/neues-verzeichnis/foo/. Diese Art der Redirects muss zum Schluss greifen und kann nicht vorgelagert werden, da ansonsten alle bestehenden 1:1- und n:1-Redirects, die bereits definiert wurden, durch eine neu eingeführte Umschreibung eines Verzeichnisses nicht mehr greifen würden.
Beispiel einer Redirect-Kaskade
Normalisierung des Protokollshttp://example.com/bar/foö/→ https://example.com/bar/foö/
Normalisierung der Subdomainhttps://example.com/bar/foö/ → https://www.example.com/bar/foö/
Normalisierung eines Umlautshttps://example.com/bar/foö → https://www.example.com/bar/fooe
Normalisierung des Trailingslashshttps://www.example.com/bar/fooe → https://www.example.com/bar/fooe/
1:1-Weiterleitunghttps://www.example.com/bar/fooe/ → https://www.example.com/bar/lorem/
Umschreiben des Verzeichnisseshttps://www.example.com/bar/lorem/ → https://www.example.com/ipsum/lorem/
Spezifikation der eintragbaren URLs
alte url
Unter Berücksichtigung der vorgenannten Redirect-Kaskaden zur Normalisierung der URLs können weiterzuleitende URLs nur in einer Standard-Form eingetragen werden, da sie ansonsten zu Konflikten mit den vorgelagerten Redirect-Kaskaden führen. Beim Eintragen einer alten URL müssen daher folgende Kriterien geprüft werden. Wird ein Kriterium verletzt, wird der Redirect nicht ins System übernommen und dem Nutzer eine Fehlermeldung unter Angabe des verletzten Kriteriums angezeigt.
- Es dürfen nur HTTPS-URLs eingetragen werden.
- Es dürfen nur URLs der eigenen Domain(s) unter Berücksichtigung der Standard-Subdomain eingetragen werden.
Hier ist zu entscheiden, welche Domains als die eigenen anzusehen sind. Gibt es neben der auch eine dedizierte, mobile Subdomain wiehttps://m.example.com/, so ist diese auch als zulässig zu definieren. Gibt es darüber hinaus weitere Domains – bspw.https://www.beispiel.de/– so ist im Detail zu klären, ob diese zulässig sind. - Die beide vorgenannten Punkte zusammengenommen dürfen somit nur absolute – keine relativen – URLs eingetragen werden.
- Es dürfen nur URLs eingetragen werden, die keine Umlaute, diakritische Zeichen oder Sonderzeichen enthalten.
- Es dürfen nur URLs mit Trailing-Slash eingetragen werden.
Darüber hinaus sind die folgenden Punkte sicherzustellen:
- Es dürfen nur solche URLs als alte URL eingetragen werden, die nicht selbst als neue URL definiert sind. Dadurch sollen Weiterleitungsketten – oder schlimmstenfalls Weiterleitungsschleifen – verhindert werden.
Bsp.: Es besteht bereits die Weiterleitunghttps://www.example.com/foo/→https://www.example.com/bar/. Die URLhttps://www.example.com/bar/kann somit nicht als weiterzuleitende URL (alte URL) definiert werden, da ansonsten für die URLhttps://www.example.com/foo/eine Weiterleitungskette entsteht.
Tritt dieser Fehler auf, wird der Nutzer durch eine Fehlermeldung in der folgenden Form darauf hingewiesen:Fehler - Weiterleitungskette: Die URL https://www.example.com/bar/ ist selbst ein Weiterleitungsziel (neue URL). Siehe ID [ID]. - Es dürfen nur solche URLs als alte URL eingetragen werden, die nicht bereits als alte URL definiert sind.
Bsp.: Es besteht bereits die Weiterleitunghttps://www.example.com/foo/→https://www.example.com/bar/. Die Weiterleitunghttps://www.example.com/foo/→https://www.example.com/lorem/kann somit nicht eingetragen werden, da die weiterzuleitende URL ansonsten zwei unterschiedliche Weiterleitungsziele hätte.
Tritt dieser Fehler auf, wird der Nutzer durch eine Fehlermeldung in der folgenden Form darauf hingewiesen:Fehler - nicht eindeutiges Weiterleitungsziel (neue URL): Die URL https://www.example.com/foo/ leitet bereits weiter auf https://www.example.com/bar/. Siehe ID [ID].
Eine Problematik hinsichtlich der weiterzuleitenden URLs, die durch die Prüfung nicht abgefangen werden kann, resultiert daraus, wenn diese als Regex angelegt sind. Hier stellt sich die Frage, wie die folgenden, weiterzuleitenden Patterns zu evaluieren sind.
^https://www.example.com/foo/.*→https://www.example.com/lorem/^https://www.example.com/foo/bar/.*→https://www.example.com/dolor/
Beide Patterns matchen die URL https://www.example.com/foo/bar/dolor/, zeigen aber auf unterschiedliche Weiterleitungsziele.
Eine Prüfung darauf, ob bei Regex-Redirects ein Zielkonflikt auftritt, ist erfahrungsgemäß schwierig zu implementieren. Auch eine Logik, dass das spezifischste Pattern den Vorzug erhalten soll, ist nicht einfach umsetzbar.
Die einfachste Lösung ist, dass derjenige Regex-Redirect, der als erstes trifft, ausgeführt wird. Im obigen Beispiel würde somit die Weiterleitung auf /lorem/ erfolgen. Der zweite Regex-Redirect wird gar nicht mehr evaluiert.
Dies kann mitunter zu unerwarteten Weiterleitungen führen, wenn ein Nutzer einen neuen Regex-Redirect einträgt, der dann gar nicht greift, weil bereits ein weiterer, ebenfalls treffender Regex-Redirect besteht – ein weiteres Faktum, weshalb musterbasierte Weiterleitungen mit Vorsicht zu genießen sind.
neue URL
- Die Eingabe der URL muss in absoluter Form erfolgen.
- Im Gegensatz zu den alten URLs kann als neue URL auch eine extern URL eingetragen werden.
- Es dürfen nur solche URLs als neue URL eingetragen werden, die nicht selbst als alte URL definiert sind. Dadurch sollen Weiterleitungsketten verhindert werden.
Bsp.: Es besteht bereits die Weiterleitunghttps://www.example.com/foo/→https://www.example.com/bar/. Die URLhttps://www.example.com/foo/kann somit nicht als Weiterleitungsziel (neue URL) definiert werden, da ansonsten für neu weiterzuleitenden URL eine Weiterleitungskette über die URLhttps://www.example.com/foo/entsteht:https://www.example.com/neue/weiterleitung/→https://www.example.com/foo/→https://www.example.com/bar/.
Tritt dieser Fehler auf, wird der Nutzer durch eine Fehlermeldung in der folgenden Form darauf hingewiesen:Fehler - Weiterleitungskette: Die URL https://www.example.com/foo/ wird selbst weitergeleitet (alte URL). Siehe ID [ID].
Automatische Redirects
Wird im System eine Seite verschoben – das heißt, eine bestehende URL ändert sich in einer Form, sodass die Seite erhalten bleibt, aber bspw. in einem anderen Verzeichnis liegt – so muss sichergestellt werden, dass die alte URL automatisch per 301 auf die neue URL weiterleitet.
Wird ein automatischer Redirect ausgeführt, ist dieser in der Übersichtstabelle zu ergänzen. Folgende Felder sind systemseitig zu befüllen
- Erstellt
Das Datum, an dem die Seite umgezogen wurde. - Bearbeiter
Hier wird “System” oder ein ähnlicher Dummy-Bearbeiter eingetragen, da beim Eintragen des Redirects durch das System der Bearbeiter, der die Seite umgezogen hat, wahrscheinlich nicht bekannt ist. - Anmerkung
Hier wird die Ursache des automatischen Redirects eingetragen – bspw. “Seite wurde verschoben”. - Typ
”automatisch” - Status Code Redirect
Da alle automatischen Redirects mittels 301 umgesetzt werden, ist dies auch die einzige Ausprägung für dieses Feld. - Parameter beibehalten
Die zugrundeliegende Einstellung ist derart, dass Query-Parameter automatisch von der weiterzuleitenden URL mitgenommen und an das Weiterleitungsziel angehängt werden. Die einzutragende Ausprägung ist somit “ja”. - alte URL / neue URL
Die URL der Seite, die verschoben o.ä wurde sowie die neue URL der Seite, auf die weitergeleitet wird.
Regelmäßige Abfrage der Status Codes und Titles der Weiterleitungsziele
Es ist wichtig, laufend den Status Code und den Browser-Title abzufragen und in der Übersichtstabelle darzustellen, damit der Nutzer Weiterleitungsziele identifizieren kann, die ggf. nicht mehr erreichbar sind oder erneut weiterleiten. Dadurch soll eine kontinuierliche Pflege der Weiterleitungen erleichtert und sichergestellt werden.
Die Abfrage des Browser-Titles dient dazu, das Thema eines Weiterleitungsziels für den Nutzer schneller erfassbar zu machen, wenn dies durch die URL an sich nicht möglich ist.
Erfahrungsgemäß ist die Abfrage der Status Codes und des Titles nicht in Echtzeit möglich, da je nach Anzahl der eingetragenen Redirects der Prozess sehr lange dauert. Es bietet sich daher an, ein Abfrageintervall von 24 Stunden zu definieren, sodass der Prozess nachts die beiden Werte erhebt und die Übersichtstabelle aktualisiert wird, sodass der Nutzer am nächsten Morgen einen aktuellen Stand vorfindet.
Aus diesem Grund wird dem Nutzer im Redirect-Editor kein Button zur ad hoc Abfrage aller Status Codes und Titles angeboten (dies ist nur für die Mehrfachauswahl möglich), da der Prozess ggf. sehr lange läuft und somit das Arbeiten blockiert.
Status Code
- Der ermittelte Status der neuen URLs wird als Status Code (
200,301 etc.) in die Spalte Staus Code neue URL geschrieben. - Alle Status Codes, die vom erwarteten Status Code
200abweichen, werden farblich hervorgehoben:- Alle Status Codes im Bereich
300bis399werden in gelb/orange hervorgehoben, wodurch eine Warnung impliziert wird. - Alle Status Codes im Bereich
400bis499werden in rot hervorgehoben, wodurch ein Fehler impliziert wird.
- Alle Status Codes im Bereich
Title
- Steht für ein Weiterleitungsziel
- Zellenwert in der Übersichtstabelle kann leer bleiben, wenn neue URL selbst weiterleitet und damit keinen Title hat.
Umgang mit parametrisierten URLs
Das Weiterleiten von parametrisierten URLs ist nicht trivial und kann hier nur in einem ersten Ansatz beschrieben werden. Die finale Ausprägung der Weiterleitungslogik wird maßgeblich durch die von der Website verwendeten Parameter und ihrer Funktionalität bestimmt. Der Umgang mit Parametern, die eine Pagination anzeigen (page=2), ist noch recht einfach umzusetzen, da hier der Parameter eine eigenständige Seite erzeugt, die auch als Verzeichnis (/2/) gedacht werden kann.
Gleiches gilt für Parameter – insbesondere Tracking-Parameter -, die den Seiteninhalt gar nicht verändern.
Wenn jedoch der Seiteninhalt durch Parameter verändert wird – bspw. Filterungen, Sortierungen, Inhalte -, muss im Detail überlegt werden, wie die Weiterleitung derartiger URLs umzusetzen ist. Sind sie als eigenständige URLs zu werten r können sie ggf. auf die kanonische URL weitergeleitet werden.
Im Vorfeld ist somit genaustens zu prüfen, welche Parameter auf der Website auftreten.
Nachfolgend wird daher nur eine exemplarische Logik beschrieben. Ihr liegt zugrunde, dass – wie oben beschrieben – die Mitnahme von Parametern an das Weiterleitungsziel optional ist.
Per Default werden die Parameter von URLs mitgenommen. Dadurch wird sichergestellt, dass bei einer Verzeichnis-Änderung paginierte Seiten 1:1 weitergeleitet werden. Im Redirect-Editor wird somit folgende Weiterleitung eingetragen:
https://www.example.com/foo/→https://www.example.com/bar/
Wird die URL https://www.example.com/foo/?page=2 aufgerufen, wird der Parameter automatisch mitgenommen und der Nutzer gelangt auf die Seite https://www.example.com/bar/?page=2. Durch die explizite Angabe an dem Redirect, dass Parameter nicht erhalten bleiben sollen, würde alle Aufrufe von paginierten Seiten auf die Seite 1 weitergeleitet:
https://www.example.com/foo/?page=2→https://www.example.com/bar/
Wird eine weiterzuleitende URL explizit mit einem Parameter angegeben, wird nur diese weitergeleitet – nicht die unparametrisierte URL:
https://www.example.com/foo/?utm_source=google→https://www.example.com/bar/- Wurde die Mitnahme des Parameters deaktiviert, wird der Nutzer auf die URL
https://www.example.com/bar/ - Wurde die Mitnahme des Parameters aktiviert, wird der Nutzer auf die URL
https://www.example.com/bar/?utm_source=google - Ruft der Nutzer die Seite
https://www.example.com/bar/– also ohne den explizit angegeben Parameter – auf, wird er nicht weitergeleitet.
- Wurde die Mitnahme des Parameters deaktiviert, wird der Nutzer auf die URL
https://www.example.com/foo/?utm_campaign=test-campaign→https://www.example.com/foo/?utm_campaign=live-campaign- Hier soll im Grunde nur der Parameter weitergeleitet werden. Dazu muss die Mitnahme des Parameters deaktiviert
- Wird die Mitnahme aktiviert, wird der Nutzer beim Aufrufen von
https://www.example.com/foo/?utm_campaign=test-campaignauf die URLhttps://www.example.com/foo/?utm_campaign=live-campaign&utm_campaign=test-campaignweitergeleitet. In diesem Fall muss somit systemseitig sichergestellt werden, dass der initiale Parameter nicht einfach nur angehängt wird (falsch:https://www.example.com/foo/?utm_campaign=test-campaign?utm_campaign=live-campaing), sondern korrekterweise mittels & mit dem neuen Parameter verknüpft wird.
https://www.example.com/foo/?utm_campaign=test-campaign→https://www.example.com/bar/?utm_campaign=live-campaign- Hier ändern sich das Verzeichnis und der Parameter. Die Logik ist zum vorherigen Punkt identisch.
- Bei deaktivierter Parameter-Mitnahme:
https://www.example.com/foo/?utm_campaign=test-campaign→https://www.example.com/bar/?utm_campaign=live-campaign - Bei aktivierter Parameter-Mitnahme:
https://www.example.com/foo/?utm_campaign=test-campaign→https://www.example.com/bar/?utm_campaign=live-campaign&utm_campaign=test-campaign

Patrick Lürwer
Senior-Analyst & Partner
In meinem Studium des Bibliotheksmanagements habe ich mich von Anfang an mehr für die Metadaten als für die Bücher interessiert. Meine Leidenschaft für Daten — das Erfassen, Aufbereiten und Analysieren — habe ich anschließend durch mein Master-Studium der Informationswissenschaft weiter ausleben und vertiefen können. Bei get:traction kombiniere ich meine Data-Hacking-Skills und meine Online-Marketing-Expertise, um datengestützte Empfehlungen für Kunden zu formulieren und umgesetzte Maßnahmen zu messen. Mein Hauptaufgabenbereich liegt dabei in der Analyse von Crawls, Logfiles und Tracking-Daten, der Konzeption von Informationsarchitekturen und der Anreicherung von Webinhalten mittels semantischer Auszeichnungen.





1 Kommentar:
[…] Redirect-Editor: Unser Kollege Patrick hat in seinem Blogartikel funktionale Anforderungen für ein effizientes & effektives Weiterleitungsmanagement definiert. […]
[…] Redirect-Editor: Unser Kollege Patrick hat in seinem Blogartikel funktionale Anforderungen für ein effizientes & effektives Weiterleitungsmanagement definiert. […]