
Recap SMX Advanced 2024 in Berlin
Anfang September fand in Berlin die SMX Advanced 2024 statt. Ich war auf dem SEO-Track unterwegs und konnte spannenden Vorträgen lauschen, viel lernen und mich mit anderen Kolleginnen und Kollegen austauschen. Auch die diesjährige Ausgabe war wieder mit internationalen Top-Speakern aus der SEO-Branche besetzt. Eine schöne Überraschung: Statt der klassischen Sitzreihen gab es runde Tische. So entstand eine gemütlichere Atmosphäre und man kam gefühlt schneller mit anderen Teilnehmern ins Gespräch. Wie im letzten Jahr fand die Konferenz in unmittelbarer Nähe des Berliner Zoos und Aquariums statt, einem meiner Lieblingsorte in der City-West. Alles in allem eine tolle Veranstaltung. Hier ein paar Highlights zum Nachlesen.

AI-Powered Search (Mike King)

Eröffnet wurde die Veranstaltung von Mike King, der in der SEO-Welt vor einigen Monaten durch seine ausführliche Berichterstattung über das jüngste Google-Leck an Popularität gewonnen hat. Mikes Keynote war ein würdiger Auftakt mit einem Rundumschlag zu aktuellen KI- und SEO-Themen, insgesamt 200 Folien und Dutzenden von KI-Tools. Hier einige meiner Take-Aways
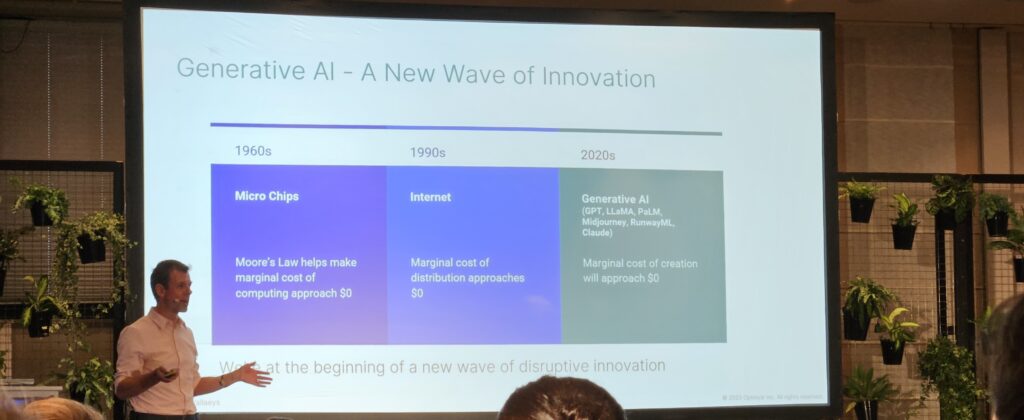
- King ist davon überzeugt, dass die generative KI ihren Ursprung in der semantischen Suche (Google) hat und zeigt dies an der Entwicklung von den ersten „vector embeddings“ Word2Vec zu Hummingbird und dann von Transformer zu BERT und schließlich zum aktuellen AIO-Modell – zumindest werden einige Zusammenhänge deutlich.
- Es ist nach wie vor wichtig, Inhalte nach Themenschwerpunkten, Autoren und Clustern zu strukturieren.
- Klicks spielen in der Google-Suche eine wichtige Rolle – daran sollte kein Zweifel mehr bestehen.
- UX wird für SEO immer wichtiger, Nutzersignale auf der Landingpage gewinnen an Bedeutung
- Interessant war der Vergleich mit dem Qualitätsfaktor (QF) der Google Ads – „Navboost“ aus den Google Leaks ist vergleichbar mit dem QF. Bei beiden spielen die erwartete Klickrate, die Relevanz der Landingpage für die Suchanfrage sowie die Relevanz der Anzeige (Title und Description) für die Suchanfrage eine Rolle.
- Letztlich geht es beim Content inzwischen um den sogenannten „information gain“ – also darum, einen inhaltlichen Mehrwert zu schaffen und nicht nur bestehende Inhalte neu zu verpacken (Stichwort „Skyscraper-Technik“), sondern völlig neue Informationen zu schaffen.
- Content Pruning: Content sollte regelmäßig auf den Prüfstand gestellt werden – King liefert dazu grundlegende Prüfpunkte und ein eigenes Ratingsystem, um überalterten Content zu identifizieren und zu priorisieren.

Darüber hinaus gibt es eine Flut von KI-Tools, die den Rahmen dieses Beitrags bei weitem sprengen würden. Dennoch lohnt es sich, einige auf ihre Nützlichkeit hin zu überprüfen, wie z.B:
- SEO-Juice – Tool für Onpage-Optimierung und interne Verlinkung
- Promptitude oder Zapier zur API-Anbindung für ein RAG
- AI-Tool zum Abgleich der Google-Richtlinien für einzelne Artikel
- AIPRM für Promptitude in Chrome
Deconstructing Google Processes to Define Your Strategy (Johan Hülsen)

Johan hat es sich nach dem DOJ-Verfahren und den Google-Leak(s) zur Aufgabe gemacht, die Prozesse von Google als Suchmaschine unter die Lupe zu nehmen und gekonnt in ihre Einzelteile zu zerlegen, um daraus Erkenntnisse für geeignete SEO-Strategien abzuleiten. Grundsätzlich gibt es sechs grundlegende Prozessschritte einer Suchmaschine, auf die man unterschiedlich einwirken kann:
- Discovery, Crawling, Indexing, Ranking, Re-Ranking, Serving
Die Schritte von der Discovery bis zur Indexierung werden natürlich stark von technischen SEO-Themen wie Sitemaps, Links, Statuscode, Robots.txt, Canonicals, Rendered Content etc. beeinflusst – also der Kunst, dass Google die eingereichten URLs findet, crawlt und indexiert. Und das ist oft leichter gesagt als getan, denn Google ist wählerisch und hat begrenzte Kapazitäten. Für die Analyse ist und bleibt der GSC der beste Freund eines jeden SEO.
In den folgenden Schritten (Ranking, Re-Ranking und Serving) geht es dann verstärkt um die Relevanz der Inhalte zur Suchanfrage sowie um Links, User Signals und Intend Matching.
Netter Trick: Man kann adhoc in der „Posting List“ über die Kennzeichnung „Über dieses Ergebnis“ in der SERP das Ranking überprüfen und ablesen, welche Begriffe für die einzelnen Suchergebnisse relevant sind. Spannend ist, dass hier auch angezeigt wird, ob andere Webseiten auf das Suchergebnis verlinken.

Beim Content ist natürlich eine wichtige Frage, ob Google die URLs (und Inhalte), die man für relevant hält und z.B. über die Sitemap einreicht, auch tatsächlich indexiert. Bei der Analyse und Optimierung geht es dann nicht zuletzt auch um die Frage, ob man für die richtige Suchanfrage und die richtige Intention optimiert. Bei den Nutzersignalen geht es dann eher in Richtung Nutzerinteraktionen mit der Website, Trafficentwicklung, Google Trends und Bounce Rate. Für das Intend-Matching sollte auf jeden Fall die SERP unter die Lupe genommen werden.
In den sechs Schritten gibt es also viele Ansatzpunkte, die man sich anschauen und optimieren kann. Insgesamt sollte man aber das große Ganze nicht aus den Augen verlieren.
Future Proof Your SEO: All You Need to Know to Stay on Top of the Game (Lily Ray)
Auch Lily Ray war wieder mit von der Partie und berichtete unter anderem, wie hart die letzten Jahre für SEO waren, was sie auch mit einer kleinen Online-Umfrage untermauerte. Außerdem hatte sie interessante Neuigkeiten über aktuelle SEO-Trends aus den USA mitgebracht:
- AI Overview (AIO) ist in den USA ein „Big Deal“, den wir hier in Europa kaum wahrnehmen, weil AIO noch nicht ausgespielt wird.
- Spannend: In AIO gibt es noch keine transaktionalen oder lokalen Ergebnisse (!).
- AIO-Tracking hält langsam aber sicher Einzug in die SEO-Tools
- Darf bei aktuellen Trends nicht fehlen: Der phänomenale Aufstieg von Foren in den Suchergebnissen. Allen voran Reddit, das Forum hat in den letzten Monaten einen noch nie dagewesenen Sichtbarkeitsboost von +2.341% (!) erzielt.
- Beim HCU (Helpful Content Update) kann sie nur von kleineren „Recoveries“ berichten. Das ist möglich, aber sehr selten. Danny Sullivans Kommentar dazu war auch nicht sehr ermutigend – „you should not expect to see traffic coming back”.
- Lilys Beobachtungen waren, dass bei den letzten großen Updates vor allem Affiliates und Informationsseiten betroffen waren und an Sichtbarkeit verloren haben.



Page Quality – Learning From the Best! (Kevin Indig)
Interessante Zahlen zum Thema Page Quality hatte Kevin Indig im Gepäck. Bei der Analyse von Trafficverlusten bei einem Kunden fiel ihm eher zufällig auf, dass gleichzeitig die Anzahl der URLs extrem anstieg. Es gab also einen hohen Anteil an Seiten mit sehr dünnem Inhalt, die letztlich auch für insgesamt weniger Traffic sorgten. Die gesamte Domain litt also unter der Masse an Seiten mit sehr geringer Page Quality. Er verglich die Ergebnisse mit der Entwicklung bei anderen Kunden und stellte fest, dass bei einigen, die über einen längeren Zeitraum die Anzahl der URLs reduziert und Page Quality aufgebaut hatten, der Traffic gestiegen war. Für Kevin ist Page Quality einer der entscheidenden Faktoren für das Ranking, aber auch für die Indexierung. Zusammenfassend lässt sich sagen, dass sich die Page Quality aus verschiedenen Faktoren zusammensetzt, die ständig überprüft und optimiert werden müssen:
Page Quality = Technical + Content + Engagement

Recap SMX Advanced 2023 in Berlin
Nach den guten Erfahrungen vom letzten Jahr habe ich mich wieder sehr auf die SMX Advanced in Berlin gefreut. Besonders schön: Der neue Veranstaltungsort im Pullman Hotel Schweizerhof lag in direkter Nachbarschaft zum Berliner Zoo, so dass ich gemütlich mit dem Fahrrad durch die Berliner City-West radeln konnte. Hier können wa gerne bleiben, I like!
Die Konferenz war, wie nicht anders zu erwarten, wieder perfekt organisiert, alle Speaker waren Top-Experten, es gab ausreichend Pausen zum Netzwerken und Austauschen mit einem internationalen Publikum. Die Moderation war klasse, Fragen konnten direkt über die Konferenz-App gestellt werden. Das ganze Ambiente stimmte einfach. Besonders hervorzuheben: In diesem Jahr gab es am ersten Tag wieder „Roundtables“ mit Experten zu ausgewählten Themen. Im klassischen Stuhlkreis konnten wir unsere Fragen stellen und diskutieren – definitiv ein Mehrwert dieser hochklassigen Veranstaltung. Mehr dazu später.
Wurde die Keynote zum Auftakt noch vor dem gesamten Publikum gehalten, so fiel danach buchstäblich die Trennwand, die den Konferenzsaal in SEO und SEA teilte. Passend dazu ging es in der Keynote zuvor um A/B-Test-getriebene Entscheidungen, die zu Wachstum führen (siehe Booking.com, Tesla, Uber, Amazon & Co, die ständig agil mit Kundenfokus testen und dadurch fast exponentiell wachsen). Man hätte auch eine Analogie zur Geschichte Berlins sehen können. Aber ich erhoffte mir natürlich ein exponentielles Wissenswachstum und keine Teilung.
Wenig überraschend war KI das Top-Thema. Bemerkenswert war aber – und auch das spricht für die Qualität der Veranstaltung -, dass das, was die Experten im letzten Jahr – allen voran Tom Anthony – vorausgesagt hatten, sich mehr als bewahrheitet hat. So wurde im letzten Jahr als Beispiel ein völlig frei erfundener Salat genannt, für den man dann ein Rezept abrufen konnte, obwohl es dieses gar nicht geben konnte. Das klang damals noch ziemlich abenteuerlich. Wer schon einmal chatGPT oder SGE genutzt hat, weiß, dass dies keine Übertreibung mehr ist.


So viel zum Einstieg, hier nun meine Highlights von sechs der insgesamt 13 Vorträge.
Tom Anthony: Entities are the past, Search is going quantum
Mitreißend bis euphorisch – die Vorträge von Tom Anthony sind ein Highlight. Nicht zuletzt wegen seines didaktischen Talents. Vor allem aber, weil er immer ganz nah dran ist an den aktuellen Trends und Entwicklungen von Suchmaschinen und KI. Auch diesmal hatte er ebenso kühne wie logische Vorhersagen, wohin die „Suche“ gehen könnte.
- Keyword Entailment und Latent Tails: Suchmaschinen werden mit KI-Technologie (wie GPT) upgegradet, um Nutzerbedürfnisse zu antizipieren und mit dynamischen Facetten/Filtern sowie neuen Keyword-Vorschlägen zu ergänzen. Diese Antizipation der KI durch das Verstehen von Zusammenhängen und Kontext über den „Latent Space“ führt zu einer Erweiterung der Long-Tail Keywords zu Latent Tail Keywords.


- Strukturierte Auszeichnungen verlieren an Bedeutung (EEAT wird umso wichtiger): Die Entitäten, die wir mühsam aufgebaut und ausgezeichnet haben, waren offenbar nur Mittel zum Zweck. Denn für GPT & Co. waren sie ideal als Label, um Kontext zu lernen. GPT mit millionenfach mehr Datenpunkten als Schema versteht nun Kontext und kann Suche und Inhalt fast mühelos zusammenführen.

- Kontext muss nicht chatbasiert sein: Beim Thema „chatGPT“ und Suche hat der „chat“-Teil keine Zukunft – viel spannender ist der „GPT“-Teil, der immer besser den Kontext versteht. LLMs (Language Learning Models) sind der wahre Schatz dieses Megatrends.
- Der GPT-Algorithmus muss mit kontextuellem Text gefüttert werden: LLMs (wie GPT4) brauchen Monate, um zu lernen. Wer in der von Tom vorhergesagten Suche präsent sein will, sollte den „First Mover Advantage“ nutzen, um im relevanten Kontext zu erscheinen.
Abschließend behauptet er, dass die Veränderungen in der Suche, wie er sie sich vorstellt, die größten seit PageRank sein werden. Mit LLMs wie GPT4 werde Googles Kontextverständnis explodieren, so Tom. Wir werden sehen, es bleibt definitiv spannend.
Bastian Grimm: The rise of AI: AI is „everywhere“ but now what?

Bastian Grimm gab in seinem Vortrag einen umfassenden Überblick über den aktuellen Stand und die Entwicklungen rund um das Thema KI und nannte immer wieder spannende Beispiele und Best Practices. Hier einige seiner Empfehlungen:
- Midjourney ist sein bevorzugtes Tool für die Erstellung von KI-Bildern.
- Prompt Builder – erstellt Prompts aus Bildern, die man hochlädt, man kann aber auch Prompts kaufen
- Unbedingt benutzen und ausprobieren: Advanced Data Analysis (ehemals Code Interpreter) und Custom Instructions bei chatGPT
Für einen guten Prompt gab es folgende Punkte, die man beachten und mitgeben sollte:
- Rolle (Wer bin ich)
- Kontext (Was ist die Situation)
- Instruktionen (Um was geht es ganau)
- Format
- Beispiele
- Einschränkungen
Und Googles SGE? Die halluziniert munter weiter. Daran wird sich laut Bastian auch in absehbarer Zeit nichts ändern, denn die Nutzer verwenden LLMs auf eine Art und Weise, für die sie nicht konzipiert wurden – sie berechnen Wahrscheinlichkeiten und treffen Vorhersagen („they are predicting“). Aber auch er findet die Funktion „SGE while browsing“ spannend, die mobil am unteren Bildschirmrand hochgezogen werden kann und auf dem Desktop eine Seitenleiste ist. Diese Funktion eignet sich hervorragend, um z.B. Seiten, auf denen man gerade surft, schnell zusammenzufassen oder weiter zu erkunden.
Weitere spannende Entwicklungen und Projekte:
- ImageBind von Meta AI: Verknüpfung von künstlicher Intelligenz „über alle Sinne“. Hier wird eine KI entwickelt, die quasi selbstständig Daten aus sechs Anwendungsarten (vereinfacht aus Bild, Text, Audio, Video, Tiefe, Wärme und Trägheit) miteinander verknüpfen kann.
- Autonomous (AI) Agents: Sollen in Zukunft als persönliche (autonome) Agents/Assistenten zur Verfügung stehen, wenn man sie mit den entsprechenden Daten trainiert. Beispiele sind AgentGPT oder WebArena. Die Hoffnung ist, dass man sich dann auf strategische Dinge konzentrieren kann, während die Agents die Umsetzung übernehmen.

Beim späteren „Roundtable“ habe ich mich zu Bastians Gruppe gesetzt, wo es natürlich um KI ging. Hier einige Punkte, die ich mitgenommen habe:
- Code Interpreter (Advanced Data Analyser) ist besonders nützlich für:
- Auswertungen der internen Verlinkung
- Logfile-Analysen
- WebPilot kann nicht gut mit JavaScript umgehen und PDF Processing ist sehr komplex – die Plugins sollten daher mit Vorsicht verwendet werden – hier können schnell Fehler passieren.
- Vertex von Google: Hier kann man (kostenlos) sein eigenes LLM erstellen.
- Der notwendige Rechercheaufwand, welche KI-Anwendungen sinnvoll sind und welche nicht, sollte eingeplant werden – für Agenturen in der Regel eher nicht abrechenbar. Hier empfiehlt sich der Aufbau kleiner interner KI-Teams.

Lily Ray: Advanced tactics for using AI tools & big data analysis to improve EEAT

Lily Rays spannender Vortrag zählte zu den praxisorientiertesten mit zahlreichen Tipps und Beispielen, welche KI-Tools und Maßnahmen gut geeignet sind, um EEAT zu verbessern.
- Perplexity AI ist z.B. geeignet, um Quellenangaben und Expertenmeinungen zu erhalten.
- KI-Tools eignen sich zum Vergleich und Verbesserung von Webseiten im Hinblick auf den sog. „Information Gain Score“ (wie viel mehr Infos auf der Seite im Vergleich zu anderen Seiten ist)
Natürlich müsse man zuerst verstehen, wie KI-Tools funktionieren, wofür sie gut sind, wofür nicht und ob KI für den Anwendungsfall überhaupt Sinn macht. Als relevante KI-Tools (bzw. LLMs) für die Content-Erstellung mit Fokus auf EEAT stellte sie Claude (mit Daten bis 2022), chatGPT (mit Daten bis 2021), Bing Chat (mit Echtzeitdaten) und BARD (mit Echtzeitdaten) vor. Lilys Liebling war eindeutig Claude. Dies sind einige der Tipps und Tricks, die sie für die Verwendung der Tools für EEAT gab:
- chatGPT mit Webpilot zur Analyse verschiedener URLs
- z. B. „Bitte vergleiche den Inhalt der folgenden 3 URLs:…“
- Website in PDF umwandeln und dann PDFs mit Claude analysieren.
- z. B. Google-Richtlinien nehmen und mit eigenen Seiten vergleichen.
- Adavanced Data Analyser von chatGPT: GSC-Daten nehmen (exportieren) und in ADA importieren, dann z.B. „Brand Keywords + gemeinsame auftretende Keywords“ aggregieren.
- Suche nach den besten Autoren in einem Bereich (bspw. über ahrefs), kombiniert mit chatGPT und WebPilot, um Autorenbiografie zu analysieren, dann daraus ein Template erstellen, das für andere Benutzer verwendet werden kann.
- Schema mit chatGPT erstellen lassen (aber unbedingt anschließend validieren lassen).
- 50 Top Headlines in chatGPT einfügen und Muster in Überschriften identifizieren, auf deren Basis neue Überschriften erstellt werden, um daraus einen Leitfaden erstellen, wie man die besten Überschriften erstellt
- „Diagrams: Show me“-Plugin: Erstellt im Handumdrehen Grafiken aus den Daten
- Mit chatGPT oder Claude FAQs erstellen oder Inhalte zusammenfassen, basierend auf dem Inhalt der Seite.
- Custom Instructions in chatGPT nutzen.
- Weitere Tools zum Anschauen: Letterdrop, harpa ai (Chrome Extension), copyleaks, ai content detector (Chrome Extension)
Abschließend berichtete sie über ihre Erfahrungen bei der Optimierung von SGE-Ergebnissen und welche Faktoren dabei eine Rolle spielen. Als Beispiel diente ihr eigener Blog. Die Punkte scheinen offensichtlich zu sein, sind aber dennoch interessant, vor allem wenn man bedenkt, wie viel Platz die SGE (nach heutigem Wissensstand) in der Suchmaschine einnehmen wird.
- Das Hinzufügen von Inhalten beeinflusste die SGE-Ergebnisse. Mehr Inhalt führte zu mehr Informationen in SGE – z.B. was ist mein Favorit, etc.
- Klare und direkte Antworten auf Fragen auf der Seite geben – das macht die SGE genauer. Fragen wählen, die die Nutzer in einem Chat stellen würden.
- Informationen müssen auf mehreren Seiten erscheinen (auch in den sozialen Medien).
Frederick Vallaeys: Advanced tactics to train and customize LLMs to optimize you ppc performance
Die Session von Frederick Vallaeys war fast ein Grundkurs in generativer KI und LLMs. Sehr professionell führte er durch die Definition von LLMs, wie sie funktionieren und halluzinieren, dahin wie man LLMs trainieren und beeinflussen kann – für mich super interessant und lehrreich. Hier mein Versuch, die wichtigsten Punkte über LLMs zusammenzufassen und wie wir sie in unserem Sinne beeinflussen können:
Grundlagen zur generativen KI:
- Generative KI macht Vorhersagen mithilfe von Sprachmodellen, nicht mit Mathematik.
- Allerdings können mathematische Aufgaben mit dem Adavanced Data Analyser (z.B. über Python) gelöst werden.
- Trainingsdaten führen zu Voreingenommenheit der Modelle, basierend auf ebendiesen Trainingsdaten
- „Change of thought prompting“: Die richtige Antwort zu „erzwingen“ kann Transparenz schaffen, indem LLM erklären werden muss, wie es zum Ergebnis kommt.
- Die Temperatur (0-2) ist eine wichtige Stellschraube, um zu beeinflussen, was bei GPT herauskommt. Soll es kreativer oder weniger kreativ sein?
- Mit dem Konzept des „Grounding“ kann Einfluss auf die LLMs genommen werden. Dabei wird quasi ein „ground truth“, also eine Grundwahrheit geschaffen, auf die sich das LLM beziehen soll.

Schritte zur Beeinflussung der LLMs:
- Das Training der größten LLMs wie LLamA-2 (von Meta), PaLM 2 (Vertext AI von Google) oder GPT-4 (von OpenAI und Microsoft) ist abgeschlossen. Daher wird beim Fine-Tuning begonnen.

- Fine-Tuning:
- Als einfachere Alternative zum Fine-Tuning können die „Custom Instructions“ in den Einstellungen von chatGPT ausgefüllt werden.
- Ansonsten geht es beim Fine Tuning darum, wie das Modell auf Basis der vorhandenen Daten reagieren soll.
- Für ein gutes Fine Tuning benötigt man mindestens 10 Beispiele, die man dem Modell mitteilt.
- Weiter Infos: https://platform.openai.com/docs/guides/fine-tuning
- Ziemlich beeindruckend war das „Prompt Chaining“, um besseren Content zu erstellen. Seine Blogbeiträge schreibt Frederick mittlerweile in etwa wie folgt:
- Er geht spazieren und diktiert seine Gedanken und Ideen (inkl. Korrekturen) als Audio-Memo ein.
- Am PC wandelt er das Transkript der Audiodatei in Text um.
- Über Claude.ai lädt er die Textdatei als Transkript hoch und bittet um eine Zusammenfassung.
- Dann wird das „Grounding“ angewendet, indem autorisierte und verbindliche Quellen und Ressourcen für den Faktenabgleich angegeben werden, mit denen der Text abgeglichen werden soll. Fehler werden korrigiert.
- Schließlich wird der Blog-Beitrag geschrieben (durch die KI).
- Etwas komplizierter ist das „Embedding“:
- Hier geht es um ein „Prompt Engineering“ – d.h. man erhält also bessere Antworten, indem man den Prompt für bestimmte Antworten (in-context) einstellt.
- Dies kann über ein „Function calling“ geschehen, indem die Antwort über eine API „embedded“ wird (z.B. eine Wetter-API für Temperaturen etc.)
- Oder etwas fortgeschrittener, das „Embedding“ von Kontext – über die sog. Vektorsuche – so können bspw. Geschäftsdaten in Vektoren umgewandelt und in einer Vektordatenbank gespeichert werden.
- Mehr Infos: https://platform.openai.com/docs/guides/embeddings/what-are-embeddings

- Als Beispieltool für die Umsetzung nennt er hier Flowwise AI, bei dem aber komplexe und technisch fortgeschrittene Schritte zur Einrichtung notwendig sind. Das Ergebnis ist dann ein „grounded“ Chatbot – so können LLMs wie z.B. Claude.ai mit verschiedenen Tools verbunden werden.
- Ein etwas einfacheres, nicht-technisches Grounding ist z.B. über Claude möglich, indem man einfach eine Textdatei mit den Infos (z.B. aus einem Buch) als „ground truth“ mit hochlädt.
- Auch KI-Bilder können in ähnlicher Weise „konfiguriert“ werden. Er empfiehlt das KI-Tool alpacaML, mit dem man sein „eigenes“ LLM fine-tunen kann. So kann man sein eigenes Design erstellen, basierend auf Beispielbildern, die man hochlädt. Als Beispiel zeigt er eine einfache Strichmännchen-Skizze, die sich nach dem Scannen in das gewünschte Design verwandelt.
Nils Rooijmans : Scripts and ChatGPT (the AI advantage)

Nils Rooijmans nahm ich als sehr sympathischen Typ wahr. Er konnte kaum unterdrücken, wie beeindruckt er von den Möglichkeiten und der Zeitersparnis durch chatGPT war. Und alle teilten sein Erstaunen – es scheint zu einfach, um wahr zu sein. Er gab sehr einfache Beispiele und Best-Practices. Hier sind meine Notizen (leicht angepasst für SEO):
Keyword-Recherche mit chatGPT4:

- Man startet mit einem „System Prompt“
- Zum Beispiel: „Verhalte dich wie ein erfahrener SEO-Berater mit hervorragenden Fähigkeiten in der Erstellung und Optimierung von Webseiten. Deine aktuelle Aufgabe ist es, eine Keyword-Recherche für einen neuen Kunden durchzuführen“.
- Man aktiviert ein Plug-in wie „WebPilot“ mit dem man Inhalte über eine URL abrufen kann.
- Und fragt einfach nach Keyword Vorschlägen zu dieser URL
- Zum Beispiel: „Erstelle einige Keyword Vorschläge für diese Zielseite: [URL] Achte darauf, dass die Keywords eine hohe Relevanz zum Inhalt der Zielseite haben. Gruppiere die Keywords in ein Fokus-Keyword und Neben-Keywords“.
Content (Text) erstellen:
- Hier gibt es grundsätzlich drei Prompt-Methoden – je mehr Beispiele, desto besser:
- Zero shot prompting (ohne Textbeispiel)
- One shot prompting (mit einem Textbeispiel)
- Few shot prompting (mit mehreren Textbeispielen)
- Das Ganze kann man dann noch „fine tunen“, indem Best-Practices für gute Texte hochgeladen und abfragt werden. Dann folgt der Bonus-Prompt: „Wie würdest du den Text ändern, basierend auf dem, was du gerade gelernt hast?“
Onpage Conversion Optimierung:
- Beginnt wieder mit einem System Prompt. Dann einfach in chatGPT4 mit Plugin eine URL abfragen: „…welche Vorschläge zur Conversion Rate Optimierung gibt es für die Zielseite…“ – optional auch mit dem Zusatz: „Formuliere die Tipps direkt als E-Mail, die ich an meinen Kunden weiterleiten kann“.
Advanced Data Analysis in chatGPT4:
- z.B. GSC-Suchanfragen auf Tagesbasis als CSV herunterladen und mit ADA in chatGPT4 importieren – eine Visualisierung vom Trend der Top 5 Suchanfragen abfragen –auch hier wieder mit einem System Prompt starten „als SEO-Berater mit hervorragenden Data Analysis Fähigkeiten…“
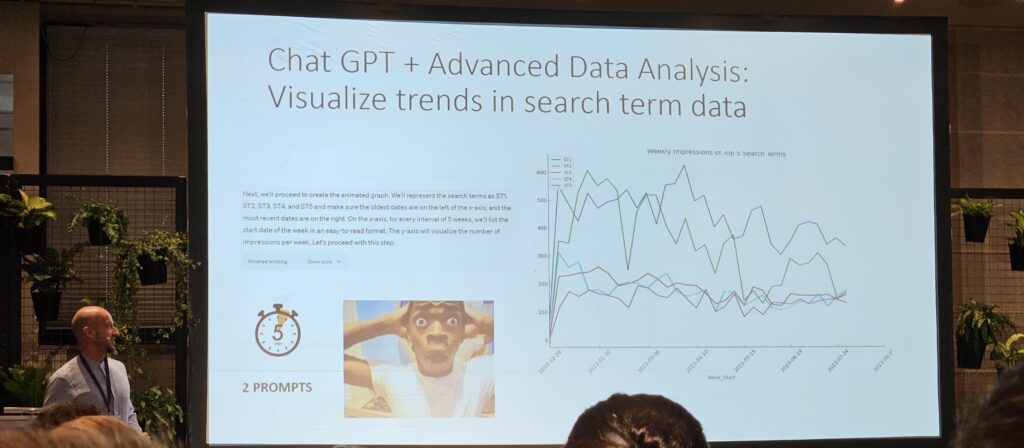
nGram-Analyse mit GPT4:
- z.B. wieder GSC-Suchanfragedaten herunterladen, in chatGPT+ADA hochladen – diesmal nach einer Analyse der Suchanfragen abfragen und – wichtig – die Daten erklären lassen.
- Der Prompt für PPC würde z.B. lauten (hier könnte man Avg. CPC mit durchschnittlicher Position ersetzen):
- „Perform bi-gram analyses.
Aggregate the number of impressions, clicks and cost per bi-gram. For each bi-gram, calculate the CTR with CTR = (clicks/impressions) * 100%, and calculate the ‚Avg CPC‘ with Avg CPC = cost/clicks
Continue with the top 20 bi-grams based on number of impression
Show the top 20 bi-grams based on impressions, as a table with download link
Visualise the top 20 bi-gram in a Dual-Axis Bar chart. Use Y axis for the number of impressions and CTR. Use the x-axis for the bi-grams. Be sure to add color gradient on the bars that represents the Avg. CPC, ranging from green (low cost) to red (high cost).”
As always, add a download link for the graph.”
- „Perform bi-gram analyses.

Abschließend zeigte er, wie man GPT4 wunderbar zum Erstellen und Testen von Skripten (JS) einsetzen kann. Einfach wieder bei GPT per System-Prompt als SEO-Experte mit hervorragenden JavaScript-Kenntnissen ein JavaScript für den gewünschten Zweck anfordern und erklären lassen, das Skript testen und anschließend von GPT korrigieren lassen, falls Fehler auftreten. Klingt einfach, ist es anscheinend auch. Sein Motto: Keine Angst haben, es einfach auszuprobieren.
Danny Zidaric und Christopher Gutknecht: How to recover from an unsuccessful SEO relaunch by activating your data
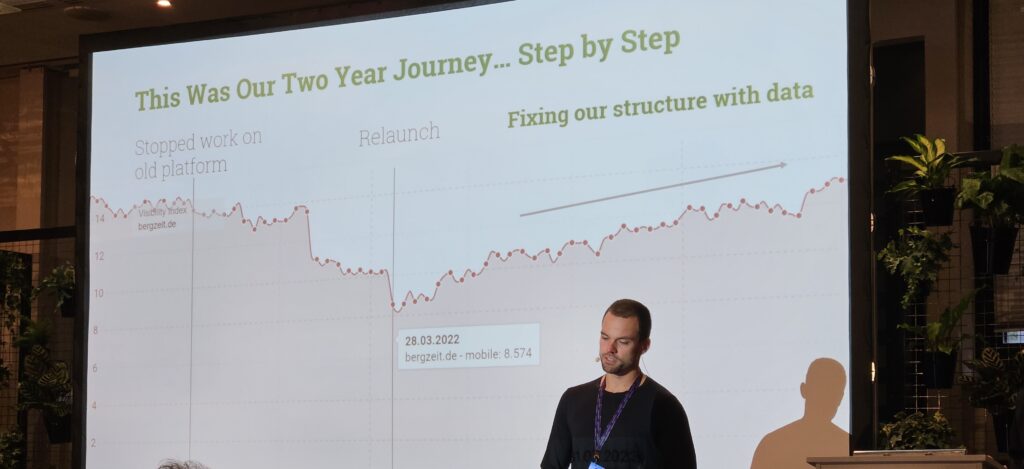
Zum Schluss noch ein Highlight ohne KI. Danny Zidaric und Christopher Gutknecht vom Online-Händler Bergzeit berichteten von ihrer Odyssee, wie sie nach einem (aus SEO-Sicht) missglückten Relaunch wieder auf die Beine gekommen sind. Spoiler: Es braucht nicht unbedingt neue, ausgefallene Tools, wichtiger ist das Monitoring und das Vertrauen in die eigenen Daten. Hier die Highlights:
- Organisatorisch wurde aufgeräumt: SEO rückte näher an das Produktteam, SEO-QA-Prozesse wurden etabliert
- Zum Monitoring von Fehlern, die nach dem Relaunch auftraten und behoben werden mussten, wie z.B. unerwünschte 4xx oder 3xx oder nutzlose JS etc. wurde ein Alerting in Teams eingerichtet (vorher über die BQ und ins GLS), so dass alle Stakeholder sofort informiert werden und sich dort auch direkt darüber austauschen können.

- Mit dem Relaunch gab es zahlreiche Kategorien ohne Nachfrage – durch die Verknüpfung der Inventurdaten mit der GSC/GA-Performance konnten sie gut gegen nicht-performante Seiten argumentieren.
- Tägliches Sitemap Monitoring mit Alert-System über Teams eingerichtet.
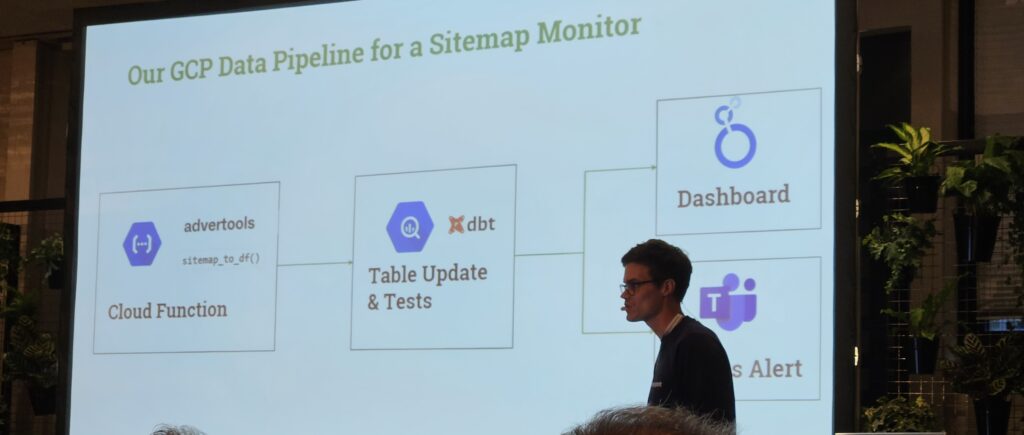
- Regelmäßiges Crawlen der Seite mit einem eigenen Crawler.
- Neben Pagetype-Reports (vs. Mitbewerber und relevante interne Seiten) wurde auch ein WebVitals-Report über die Pagespeed-API eingerichtet – alles wieder über BigQuery und Google Looker Studio (GLS) Dashboards mit Alerts in Teams.

Fazit
Natürlich gab es noch viel mehr – für mich insgesamt 13 Vorträge in zwei Tagen, alle mit starken Inhalten. Die sechs ausführlichen Beiträge, darunter zwei SEA-Vorträge, waren für mich jedoch am interessantesten. Sie zeigten, mit welcher Routine und Selbstverständlichkeit bereits mit KI-Tools gearbeitet wird und zusehends Methoden entwickelt werden, mit denen die Arbeit im SEO-Bereich effektiver wird. Dies liegt m.E. unter anderem daran, dass der englischsprachige Raum früher und einfacher Zugang zu KI-Technologien hatte und hier als erstes ausprobieren konnte. Auch der Anteil englischsprachiger Ressourcen für KI-Trainingsdaten war (ist) deutlich größer.
Während die Vortragenden meist über die Flut von chatBot-Videos und Twitter(X)-Beiträgen über KI-Tooltipps scherzten, kam mir das meiste dann doch ähnlich überwältigend vor. „Nimm Tool-xy, mache dies, frage das, gebe das ein und siehe da, ich muss nichts mehr machen und habe x Stunden gespart.“ – Es klingt oft so einfach, aber in Wirklichkeit muss auch dies mühsam neu gelernt werden. Nils Rooijmans, der sympathische Niederländer mit den chatBot-Prompts und JaveScripts, hat es, wie ich finde, sehr treffend formuliert: „Die Leute (wir) brauchen keine Angst zu haben: Nicht die KI-Technologie wird unsere Jobs wegnehmen, sondern Mitbewerber und Kollegen/innen, die damit umgehen können und effektiver werden als wir.“ (sinngemäß übersetzt)

Andreas Föll
SEO Consultant
2008 weckte ein Webdesign-Seminar im Rahmen meines International Business Studiums in England meine Faszination für den Onlinebereich. Neben den Grundkonzepten eignete ich mir schnell HTML- und CSS Kenntnisse an, um Internetseiten zu bauen, zu pflegen und sichtbar zu machen. Mich begeistert die Kombination aus technischem Verständnis, Struktur und kreativem Denken. Im anschließenden Marketingstudium konzentrierte ich mich weiter auf den Onlinebereich und vertiefte mein Marketingwissen; beruflich war in verschiedenen Branchen teils auch international im Online-Marketing und E-Commerce tätig. Bei get:traction kann ich mich seit Anfang 2022 voll auf die organische Suchmaschinenoptimierung konzentrieren – mein absoluter Lieblingsbereich – und freue mich, in einem brillanten Team aus SEOs, Analysten und Redakteuren, erfolgreich spannende Kundenprojekte voranzubringen und umzusetzen.



