
Ich muss leider mit einem Problem beginnen, das wohl viele von uns kennen. Stell Dir dazu kurz vor, dass Dein Kunde Deine Analyse nach einem halben Jahr in der Schublade wiedergefunden hat und jetzt gerne mit der Umsetzung Deiner Maßnahmen beginnen möchte. Oder Du bist Angestellter in einem Unterneh-men und das Management hat Dir endlich die Ressourcen zur Verwirklichung bereitgestellt. So oder so, es ist einige Zeit vergangen, Du hast Dich anderen Dingen gewidmet und um ehrlich zu sein, weißt Du nicht mehr so genau, was und wie Du damals im Detail analysiert hast.
Alles kein Problem, schnell das Analysedokument wieder hervorgekramt, reingeschaut – sieht alles echt gut aus, hast Dir damals wirklich etwas dabei gedacht. Beispielsweise das Diagramm hier gefiel Deinem Kunden / Vorgesetzten wirklich gut:

Damals wusstest Du natürlich ungefähr, für welche Seiten die unbeschrifteten Punkte stehen. Heute… – natürlich nicht mehr. Also gut, auch kein Problem: Excel-Datei mit den Daten suchen. Excel-Datei in einem anderen Ordner als dem Ordner mit der Analyse-Datei finden. Vergangenheits-Ich verfluchen, weil es mal wieder nichts dokumentiert hat. Das richtige Tabellenblatt suchen (Tabelle 34, ist doch logisch, hättest Du auch direkt drauf kommen können). Formeln suchen. Formeln verstehen. Excel-Datei suchen, die in der Formel referenziert wird, suchen. Sich für das nächste Mal wirklich, wirklich, wirklich vornehmen, alle Dateien besser zu strukturieren und alle Arbeitsschritte zu dokumentieren.
Oder anders herum. Da jetzt ein halbes Jahr vergangen ist, haben sich natürlich die Page Views geändert. Außerdem hast Du ein bisschen an der internen Verlinkung herumgeschraubt. Auch kein Problem: Excel auf, neuen Crawl importieren. Ach ja, Du hast die URLs ja vorher segmentiert. Wo liegen noch mal die Segment-Muster? Gut, passt wieder. Aktuelle Google Analytics-Daten an die URLs schreiben. Damals natürlich nicht mit Analytics Edge abgefragt, also doch wieder manuell Hand anlegen.
Ok, ich höre ja schon auf. Ich denke, Du fühlst den Schmerz und weißt, was ich meine.
Wir haben hier also ein massives Problem, was sehr viel Zeit, Geld und vor allem Nerven kostet. Denn im Grunde darf keiner dieser Arbeitsschritte nötig sein. Jede Analyse sollte zu jedem Zeitpunkt nachvollziehbar und reproduzierbar sein. Warum stehen wir dennoch immer wieder vor dem gleichen Problem? Dazu ein kleiner Abstecher in die Theorie.
Prozessschritte einer Datenanalyse
Jeder Analyseprozess besteht aus vier bzw. fünf Teilschritten. Als Erstes müssen die Daten aus den jeweiligen Quellen (Datenbanken, APIs, CSVs, usw.) in das Analyse-Tool – meistens Excel – importiert werden. Im nächsten Schritt werden die Daten aufgeräumt, um sie für den nachfolgenden Prozessschritt handhabbar zu machen. Aufräumen meint unter anderem das Normalisieren von Werten, weite in lange Tabellen überführen, Daten im JSON-Format in tabellarische Form bringen et cetera.
Nun folgt die eigentlich spannende Tätigkeit: das Verstehen. Das Verstehen ist dabei ein iterativer Prozess aus Datentransformation und -visualisierung. Du formulierst Fragen, die Du an die Daten stellst. Um sie zu beantworten, musst Du die Daten in den meisten Fällen in eine aggregierte Form bringen. Konkret möchtest Du beispielsweise wissen, wie häufig welcher Status Code in einem Crawl vorkommt. Oder Du reduzierst die täglichen Rohdaten aus der Google Search Console (GSC) respektive Google Analytics (GA) auf eine höhere Zeitebene, sprich: Monate, Quartale, Jahre. Transformation heißt auch, dass Du die Rohdaten um zusätzliche Dimensionen anreicherst, indem Du beispielsweise URL- oder Phrasensegmente bildest. Die Transformation wechselt sich mit der Visualisierung ab. Denn Auffälligkeiten in den Daten sind in Diagrammen zumeist einfacher zu erkennen als in den zugrundeliegenden Tabellen.
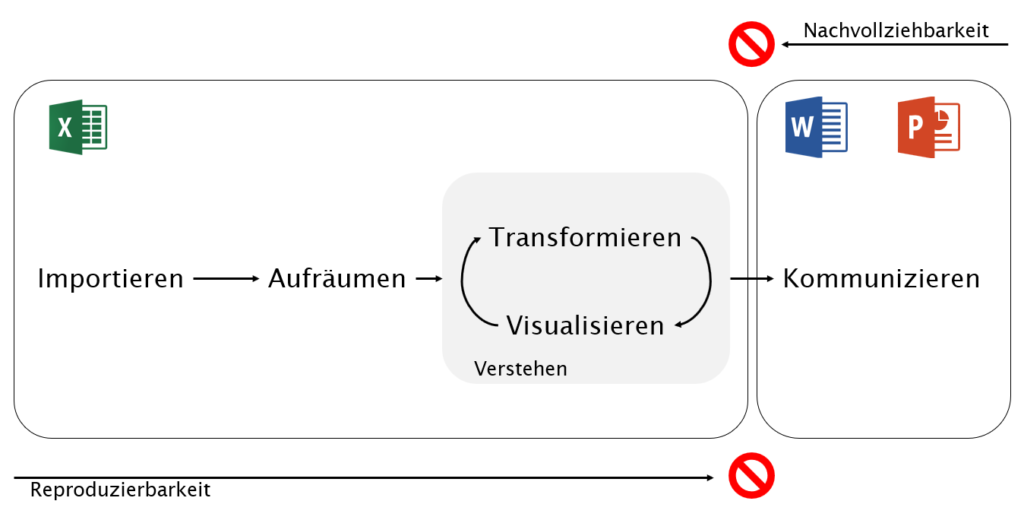
Während dieser explorativen Datenanalyse überführst Du Deine Einsichten in ein Dokument, mit dessen Hilfe die Insights an den jeweiligen Empfänger kommuniziert werden sollen. Das ist zumeist Word oder Power Point. Und an dieser Stelle tritt der Bruch ein, der das oben beschriebene Problem bedingt. Analyse und Kommunikation finden in unterschiedlichen Anwendungen statt. Möchten Du oder der Empfänger auf die zugrundeliegenden Daten zugreifen, ist das nicht mehr ohne weiteres möglich, denn sie sind nicht aneinandergekoppelt. Natürlich kannst Du im Word immer wieder auf die entsprechende Excel(-Tabelle) hinweisen, aber das ist unglaublich mühsam und fehleranfällig. Meistens lässt man es dann doch … wird schon keiner nachfragen.
Und von der anderen Richtung kann das finale Dokument nicht unmittelbar – beispielsweise mit aktualisierten Daten – neu generiert werden. Im Grunde musst Du jedes Diagramm und jede Beschreibung noch einmal anfassen.
Und dann bleibt noch der Punkt mit der Dokumentation. Selbst wenn Du Dir in Excel eine Power Query-Abfrage gebaut hast, die das Importieren und Transformieren der Daten weitestgehend automatisiert und somit reproduzierbar macht, ist Excel einfach nicht dafür ausgelegt, eine umfassende Dokumentation der einzelnen Schritte zu erstellen. Und sind wir ehrlich, niemand mag seine Arbeit dokumentieren, und wenn es einem das Tool dann auch noch extra schwer macht, nehmen wir das doch gerne als Vorwand, um es dann ganz sein zu lassen. Ist dann ja nicht mein Problem, sondern das des Zukunft-Ichs.
So, ich denke, das waren genug Probleme. Wie sieht die Lösung aus? – Mit einem Buchstaben gesagt: R.

Mit etwas mehr Buchstaben: R + RStudio + RMarkdown. R ist eine statistische Programmiersprache. Kernmerkmale sind, dass sie sich sehr gut auf Daten in tabellarischem Format versteht und ein umfangreiches Spektrum an Funktionen zur Datentransformation, -aggregation und -visualisierung bietet. Also all das, was wir brauchen. RStudio ist eine IDE, eine graphische Oberfläche, die auf R, das standardmäßig auf der Kommandozeile ausgeführt wird, aufsattelt und somit die Handhabung deutlich vereinfacht und komfortabler macht. RMarkdown schließlich ist eine Library, die es ermöglicht, R-Skripte und Markdown in einer Datei zu verwenden, um daraus direkt Dokumente zu erzeugen.
Aber genug der theoretischen Hinführung. Die Vorteile werden am konkreten Beispiel am deutlichsten.
RStudio & RMarkdown: Eine schnelle Einführung
Zwei Hinweise noch vorweg: Ich kann an dieser Stelle natürlich keine Einführung in R bieten. Ich denke aber, dass die Syntax und die verwendeten Funktionen weitestgehend selbsterklärend sind. Ich beschreibe daher nur grob, was die einzelnen Code-Abschnitte tun. Solltet Ihr durch diesen Beitrag Lust bekommen haben, Euch mit R zu befassen, findet Ihr im Internet eine Vielzahl an Tutorials zur Installation und ersten Schritten in R und RStudio. Wenn Ihr Euch tiefergehend mit der Thematik beschäftigen wollt, kann ich Euch die Online-Lern-Plattform https://www.datacamp.com wärmstens ans Herz legen. Einige Kurse sind dort kostenlos, sodass Ihr euch einen ersten Eindruck verschaffen könnt. Ein Buch, das nicht nur R, sondern vor allem auch die zugrundeliegenden Konzepte der Daten Analyse sehr gut vorstellt, ist R for Data Science von Hadley Wickham. Dem Autor der Library tidyverse, die ich im Folgenden ausgiebig verwenden werde. Das Buch könnt Ihr auch online unter https://r4ds.had.co.nz/ kostenlos lesen.
🎁 Um Euch das Abtippen / Kopieren zu ersparen, findet Ihr den Code hier zum Downloaden:
https://github.com/netzstreuner/r4seo_reproduzierbare_analysen
Legen wir los!
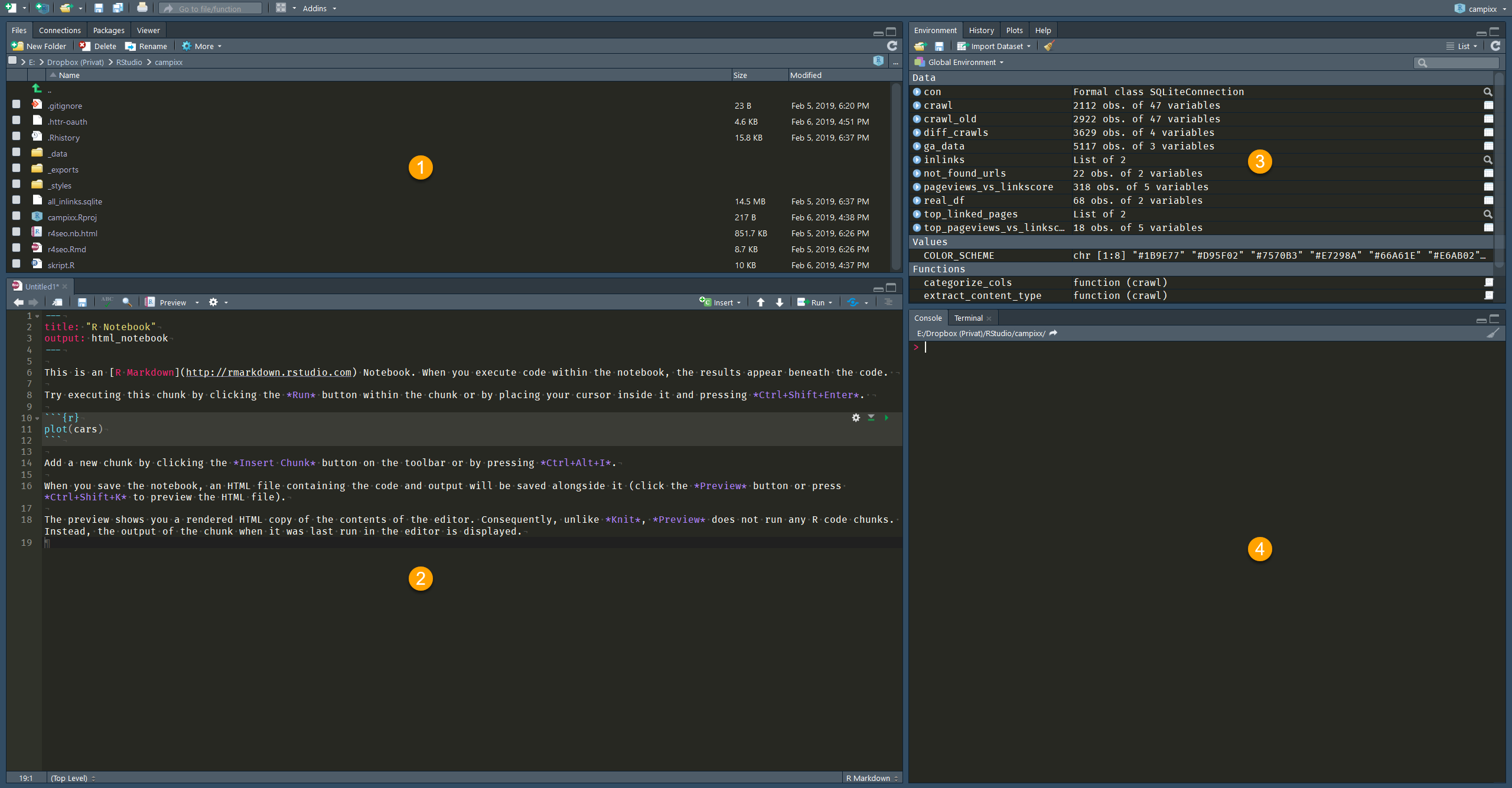
Damit Ihr eine grobe Vorstellung davon bekommt, wovon ich überhaupt rede, hier ein Screenshot von RStudio. (1) ist der File Explorer. Hier seht Ihr Eure Skripte, Ordner, CSVs et cetera. (2) ist der Code Editor, in dem Ihr Skripte schreibt. (3) ist das Environment. Wenn Ihr Variablen oder Funktionen definiert, werden sie Euch hier angezeigt. (4) ist die Console, auf der Nachrichten vom Code ausgegeben werden. Oder Ihr nutzt sie, um ad hoc Code auszuführen, der nicht Bestandteil des Skripts sein soll.
Im linken, unteren Panel (2) habe ich bereits ein sogenanntes R-Notebook erzeugt, das standardmäßig eine Beispiel-Befüllung enthält. Im Detail sieht es wie folgt aus:

Durch einen Mausklick kann das Notebook gerendert werden, sodass ein HTML-Dokument erzeugt wird.
Im GIF seht Ihr, wie ich zuerst einen sogenannten Code-Chunk ausführe, der einen Plot generiert. Dazu gleich im Detail mehr. Anschließend rendere ich den Output. Da das Format ein HTML-Dokument ist, bietet es eine gewisse Interaktivität. Zu sehen ist, wie ich den Code, der den Plot generiert, ein- und ausklappe. Für eine Zeile Code ist das recht müßig, aber Ihr seht hier das Key-Feature, welches die Dokumentation der Analyse ermöglicht. Da jederzeit der zugrundeliegende Code des Notebooks angezeigt werden kann, dokumentiert sich die Analyse quasi selbst. In Kombination mit Kommentaren im Code ist dadurch jederzeit nachvollziehbar, wie Daten transformiert oder aggregiert wurden, um die Tabellen oder Plots im Output-Dokument zu erstellen.
Im folgenden Screenshot seht Ihr das Notebook und den Output noch einmal gegenübergestellt, damit Ihr im Detail nachvollziehen könnt, welche Elemente wie gerendert werden.

Am Anfang des Notebooks seht Ihr ein YAML, über das Meta-Angaben wie der Titel und das Output-Format definiert werden können. Anschließend folgt ganz normaler Text in Markdown-Syntax. Das Besondere an den Notebooks sind die in Backticks eingefassten Code-Chunks. In diesen kann R-Code geschrieben werden, der beim Rendering des Notebooks ausgeführt wird. Analyse-Code und Beschreibung der Insights stehen somit in einem Dokument und bilden eine Einheit, die jederzeit erneut ausgeführt werden kann.
Konfiguration des Notebooks
Nachdem Ihr gesehen habt, wie R-Notebooks grundsätzlich funktionieren, möchte ich Euch exemplarisch durch die einzelnen Analyse-Schritte führen. Dazu lösche ich den gesamten Beispielinhalt und beginne, meinen eigenen zu schreiben.
Zunächst gilt es, das Notebook resp. das daraus resultierende Analyse-Dokument zu konfigurieren. Wie bereits erwähnt, könnt ihr mittels YAML bestimmte Meta-Angaben und Einstellungen definieren. Meine sehen so aus:
---
title: "R4SEO"
author: "Patrick"
date: "2019-02-07"
output:
html_notebook:
code_folding: hide
css: _styles/rnotebook_style.css
number_sections: yes
toc: yes
---
Außerdem kann ohne Weiteres auch noch ein Logo eingehängt werden.
htmltools::img(src = knitr::image_uri("_styles/get_traction.jpg"),
style = 'position:absolute; top:0; right:0; pad-ding:10px;width:100px;height=100px')
Hinweis: Immer, wenn ich wie gerade Code-Snippets angebe, müsst Ihr Euch die einfach als Code-Chunk denken. Der Übersichtlichkeit halber verzichte ich auf die Einfassung.
Das Resultat sieht dann wie folgt aus.

Wie Ihr im YAML seht, können über eine normale CSS-Datei Formatierungen vorgenommen werden. Hier ändere ich exemplarisch Font und unterstreiche Überschriften. Außerdem lasse ich automatisch ein Inhaltsverzeichnis basierend auf den nummerierten Überschriften generieren. Je nach Empfänger der Analyse macht es Sinn, den Code immer in eingeklappter Form einzubinden, um den Textfluss nicht unnötig zu stören.
Daten importieren und aufbereiten
Gut, beginnen wir mit der eigentlichen Arbeit. Als Erstes müsst Ihr natürlich die benötigten Daten importieren. Als Beispiel verwende ich hier zwei Screaming-Frog-Crawls – einen aktuellen und einen älteren. Letzteres dient später dazu, zu prüfen, welche Veränderungen es zwischen zwei Zeitpunkten auf der Website gab.
Ach ja, eins noch vorweg: Für die nachfolgenden Arbeiten benötigen wir zwei Packages, die den Funktionsumfang von R erweitern. Das ist zum einen tidyverse, eine sehr mächtige Sammlung verschiedenen Sub-Packages zum Einlesen, Aufbereiten und Visualisieren von Daten, zum anderen janitor. Letzteres stellt einige komfortable Hilfsfunktionen bereit, um Daten ad hoc zu aggregieren. Eine sehr gute Einführung in die Syntax und die wichtigsten Funktionen von tidyverse findet Ihr in dieser Präsentation. Die beiden Packages ladet Ihr, indem Ihr den nachfolgenden Code direkt unterhalb des YAML einfügt.
```{r message=FALSE, include=FALSE}
library(tidyverse)
library(janitor)
```
Einige Libraries geben beim Laden eine Nachricht aus. Die wollt Ihr natürlich nicht im Analyse-Dokument haben. Auch der Code an sich macht im Output-Dokument keinen Sinn. Dem Empfänger dürfe egal sein, welche Packages Ihr verwendet. Daher kann auf Ebene der einzelnen Code-Chunks sehr genau definiert werden, wie diese sich beim Rendern verhalten sollen. Hier unterdrücke ich mit `message=FALSE` die Lade-Nachricht und mit `include=FALSE` die Darstellung des Codes.
So, jetzt aber wirklich an die Arbeit. Daten laden. Wie gesagt, wir brauchen zwei Crawls. Diese habe ich in einem Unterverzeichnis `_data` abgelegt. Dadurch schaffe ich Ordnung in meinem Workspace, indem ich Skript-Dateien, Daten und – später – Exporte voneinander trenne.
Das Laden geht denkbar einfach mit einer Zeile Code von der Hand.
crawl <- read_csv("_data/internal_all_2019-02-05.csv", skip = 1)Die Funktion `read_csv` liest die Datei des angegebenen Pfades ein. Der Screaming Frog schreibt immer einen Kommentar in die erste Zeile der CSV, die wir hier mit `skip = 1` direkt überspringen. Die Daten werden eingelesen und in einen sogenannten DataFrame, sprich: eine Tabelle, in der Variable `crawl` gespeichert. So sieht sie aus.

Die Spaltennamen sind für ein programmatisches Umfeld recht unschön. Sie enthalten Groß- und Kleinschreibung sowie Leer- und Sonderzeichen. Wollt Ihr die Spalten in der jetzigen Form ansprechen, müsstet Ihr sie jedes Mal in Backticks einfassen, da andernfalls das Leerzeichen die Ausführung unterbricht. Also schnell eine kleine Hilfsfunktion hinzugenommen. `clean_names()` normalisiert die Benennung automatisch.
crawl <- read_csv("_data/internal_all_2019-02-05.csv", skip = 1) %>%
clean_names()

Genauso wie die Spaltenüberschriften liegen einige der Spaltenwerte in Groß- und Kleinschreibung vor. Das ist problematisch, wenn Ihr bspw. wissen wollt, wie häufig welcher Content Type vorkommt.
Hinweis: Wenn Ihr im Folgenden Code seht, der mit `>` eingeleitet wird, sind das Eingaben, die ich auf der Konsole durchgeführt habe. Sie sind also kein Bestandteil des Analyseskripts, sondern dienen nur dazu, schnell einen Blick auf die Daten zu werfen.
> crawl %>% + count(content) # A tibble: 8 x 2 content n <fct> <int> 1 application/javascript 447 2 image/gif 1 3 image/jpeg 1124 4 image/png 146 5 text/css 31 6 text/html 6 7 text/html; charset=utf-8 355 8 NA 2
Hier dürfte Euch erst einmal egal sein, ob UTF nun groß- oder kleingeschrieben ist. Entsprechend definiert Ihr Euch eine eigene Funktion, die die Werte der angegebenen Spalten zu Kleinbuchstaben ändert.
normalize_cols <- function(crawl) {
crawl %>%
mutate_at(c("content",
"status",
"meta_robots_1",
"indexability",
"indexability_status"),
tolower)
}
Diese wendet Ihr dann ebenfalls auf den Crawl an.
crawl <- read_csv("_data/internal_all_2019-02-05.csv", skip = 1) %>%
clean_names() %>%
normalize_cols()
Wie Ihr im obigen Screenshot gesehen habt, gibt es nach der Normalisierung immer noch zwei Ausprägungen für HTML-Seiten – mit und ohne Angabe des Character-Encodings. Euch interessiert aber nur, ob es eine HTML-Seite ist. Genauso ist die Angabe des Bildformats zu spezifisch – Image allein reicht vollkommen aus. Daher definiert Ihr eine weitere Funktion, die die Werte der Spalte `content` auf weniger Ausprägungen reduziert und in die neue Spalte `content_type` schreibt.
extract_content_type <- function(crawl) {
crawl %>%
mutate(content_type = case_when(str_detect(content, "html") ~ "HTML",
str_detect(content, "javascript") ~ "JavaScript",
str_detect(content, "css") ~ "CSS",
str_detect(content, "image") ~ "Image",
str_detect(content, "pdf") ~ "PDF",
str_detect(content, "flash") ~ "Flash",
TRUE ~ "Other"))
}
> crawl %>% + count(content_type) # A tibble: 5 x 2 content_type n <fct> <int> 1 CSS 31 2 HTML 361 3 Image 1271 4 JavaScript 447 5 Other 2
Bei Analyse ist es immer sinnvoll, einzelne Website-Bereiche getrennt voneinander zu betrachten. Klassisch kann hier nach Seiten-Templates (Startseite, Produktübersichtsseite, Produktdetailseite usw.) differenziert werden. Insbesondere bei Verlagswebsites bietet sich zusätzlich eine inhaltliche Segmentierung nach Ressorts (Politik, Wirtschaft, Feuilleton etc.) an. Auch hierfür definiert Ihr eine Funktion und wendet sie auf den Crawl an.
# URLs segmentieren
segment_urls <- function(crawl) {
crawl %>%
mutate(seg_seitenbereich = case_when(content_type == "HTML" & str_detect(address, "^https?://www.barf-alarm.de/$") ~ "Startseite",
content_type == "HTML" & str_detect(address, "^https?://www.barf-alarm.de/(shop|produkt)/") ~ "Shop",
content_type == "HTML" & str_detect(address, "^https?://www.barf-alarm.de/blog/") ~ "Blog",
content_type == "HTML" ~ "Sonstige"))
}
Schließlich gebt Ihr noch an, bei welchen Spalten es sich um kategoriale Daten handelt. Das heißt, die Werte in der jeweiligen Spalte können nur eine bestimmte Anzahl an vorgegebenen Ausprägungen annehmen. In der Spalte `indexibility` kann bspw. nur `indexable` oder `non-indexable` stehen. Wichtig ist dies insbesondere bei Spalten wie dem Status Code, deren Werte zunächst Zahlen sind (`200`, `301`, `404` etc.). Auf den konkreten Grund gehe ich später im Detail ein.
categorize_cols <- function(crawl) {
crawl %>%
mutate_at(c("content",
"status",
"status_code",
"indexability",
"indexability_status",
"meta_robots_1",
"content_type"),
factor)
}
In Summe sehen das Einlesen und Aufbereiten wie folgt aus. Da Ihr die Aufbereitung als Funktionen definiert habt, könnt ihr Sie natürlich ohne Weiteres sowohl auf den aktuellen als auch auf den alten Crawl anwenden.
# aktueller Crawl
crawl <- read_csv("_data/internal_all_2019-02-05.csv", skip = 1) %>%
clean_names() %>%
normalize_cols() %>%
extract_content_type() %>%
segment_urls() %>%
categorize_cols()
# alter Crawl
crawl_old <- read_csv("_data/internal_all_2018-10-25.csv", skip = 1) %>%
clean_names() %>%
normalize_cols() %>%
extract_content_type() %>%
segment_urls() %>%
categorize_cols()
Ad-hoc-Betrachtung der Daten
Oben habt Ihr das Package `janitor` geladen. Janitor macht das Betrachten von Daten on the fly wunderbar einfach.
Wollt Ihr wissen, wie häufig die einzelnen Content Types vorkommen, könnt Ihr den `crawl` an die Funktion `tabyl()` geben. Neben dem Aufkommen erhaltet Ihr damit auch direkt die Anteile.
> crawl %>%
+ tabyl(content_type)
content_type n percent
CSS 31 0.0146780303
HTML 361 0.1709280303
Image 1271 0.6017992424
JavaScript 447 0.2116477273
Other 2 0.0009469697
`adorn_totals()` (adorn = schmücken) fügt eine Zeile mit der Summe hinzu.
> crawl %>%
+ tabyl(content_type) %>%
+ adorn_totals()
content_type n percent
CSS 31 0.0146780303
HTML 361 0.1709280303
Image 1271 0.6017992424
JavaScript 447 0.2116477273
Other 2 0.0009469697
Total 2112 1.0000000000
Die Prozent-Formatierung ist recht unleserlich. `adorn_pct_formatting()` schafft Abhilfe.
> crawl %>%
+ tabyl(content_type) %>%
+ adorn_totals() %>%
+ adorn_pct_formatting()
content_type n percent
CSS 31 1.5%
HTML 361 17.1%
Image 1271 60.2%
JavaScript 447 21.2%
Other 2 0.1%
Total 2112 100.0%
In gleicher Weise könnt Ihr bspw. überprüfen, wie häufig jeder Status Code bei jedem Content Type vorkommt.
> crawl %>%
+ tabyl(status_code, content_type) %>%
+ adorn_totals(c("row", "col")) %>%
+ adorn_percentages() %>%
+ adorn_pct_formatting(0) %>%
+ adorn_ns() %>%
+ adorn_title()
content_type
status_code CSS HTML Image JavaScript Other Total
0 0% (0) 0% (0) 0% (0) 0% (0) 100% (2) 100% (2)
200 2% (31) 15% (314) 62% (1271) 22% (447) 0% (0) 100% (2063)
301 0% (0) 100% (34) 0% (0) 0% (0) 0% (0) 100% (34)
404 0% (0) 100% (8) 0% (0) 0% (0) 0% (0) 100% (8)
500 0% (0) 100% (5) 0% (0) 0% (0) 0% (0) 100% (5)
Total 1% (31) 17% (361) 60% (1271) 21% (447) 0% (2) 100% (2112)
Visualisierung der Crawl-Daten mittels ggplot
Mit den oben gezeigten Funktionen könnt Ihr Euch einen schnellen Überblick verschaffen. Wesentlich intuitiver für das Verständnis von Mengengerüsten sind allerdings Diagramme – insbesondere bei der Kommunikation der Analyse.
Im Folgenden zeige ich Euch daher, wie Ihr ein Barchart der Status Codes plotten könnt. Hier zunächst einmal der Code, den wir gleich Schritt für Schritt durchgehen.
crawl %>%
count(status_code) %>%
ggplot(aes(x = status_code, y = n, fill = status_code)) +
geom_col() +
geom_text(aes(label = n), vjust = -.3, size = 3) +
guides(fill = F) +
theme_light() +
labs(title = "Status Codes",
subtitle = "von barf-alarm",
x = "Status Codes",
y = "Anzahl URLs",
caption = paste0("Stand: ", Sys.Date())) +
theme(plot.title = element_text(face = "bold"),
plot.subtitle = element_text(color = "#666666"),
plot.caption = element_text(color = "#AAAAAA", size = 10)) +
scale_fill_manual(values = COLOR_SCHEME)
Ihr gebt den aktuellen Crawl an die `count()`-Funktion, die das Aufkommen der einzelnen `status_codes` zählt. Das kennt Ihr im Prinzip schon von den obigen Screenshots. Das Ergebnis ist eine Aggregationstabelle. Diese leitet Ihr wiederum an die Plotting-Funktion `ggplot()`. Innerhalb dieser definiert Ihr, dass der Status Code auf der x-Achse, die Anzahl (n) auf der y-Achse dargestellt werden soll. Außerdem gebt Ihr noch an, dass die Balken entsprechend der Status Codes eingefärbt werden sollen (`fill`). Dazu gleich mehr. Führt Ihr den Code bis hierhin – also bis zur und einschließlich der dritten Zeile – aus, erhaltet Ihr zunächst nur folgenden Plot.
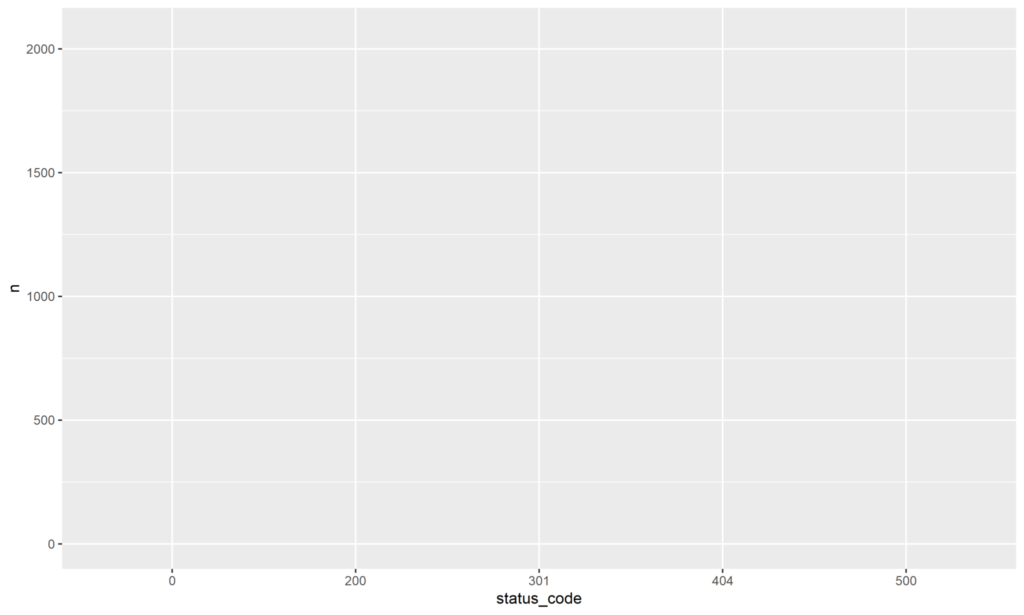
`ggplot()` zieht zunächst einmal nur eine Leinwand und das Koordinatensystem auf, auf der die Daten dargestellt werden sollen. Ihr habt allerdings noch nicht angegeben, welche Art von Diagramm verwendet werden soll. Das macht Ihr mit `geom_bar()`. Der Code bis dort ausgeführt, plottet das nachfolgende Diagramm.

An dieser Stelle wird nun auch ersichtlich, warum wir bei der Aufbereitung der Crawl-Daten die Spalte `status_code` als kategorial definiert haben. Derartige Daten werden von `ggplot()` automatisch mit möglichst unterschiedlichen Farbwerten geplottet. Hättet Ihr dies nicht getan, würde `ggplot()` den Status Code, der ja aus Zahlenwerten besteht, als kontinuierlichen Datentyp auffassen und entsprechend ein kontinuierliches Farbspektrum verwenden. An der Legende könnt Ihr den Unterschied sehr gut erkennen.

Mittels `geom_text()` gebt Ihr an, dass die Anzahl der Status Codes noch einmal als Label über die Balken geschrieben werden soll. Ich hoffe, langsam wird deutlich, wie Plotting mittels `ggplot()` funktioniert. Ihr tragt Schicht für Schicht auf die Leinwand auf, bis Ihr das gewünschte Aussehen konfiguriert habt. Eigentlich auch nicht wesentlich anders im Vergleich zu Excel, nur dass Ihr tippt statt in Dropdowns zu klicken.

Die Legende ist redundant, denn die farblichen Balken dienen allein der schnellen visuellen Unterscheidbarkeit. Sie encodieren hier nicht unbedingt eine zusätzliche Information. Also unterdrückt Ihr die Generierung der Legende via `guides(fill = FALSE)`.

Der graue Hintergrund ist meiner Meinung nach sehr aufdringlich. Also verwende ich hier ein helleres Theme `(theme_light())`.

Bisher habt Ihr nur die Darstellung der Daten beeinflusst. Natürlich können auch die Textelemente des Plots verändert werden. Mittels `labs()` gebt Ihr die Beschriftung an. `theme()` dient dazu, ihre Darstellung genauer zu formatieren. Der Titel soll fett geplottet werden, Untertitel und Caption in Grau.

Zu guter Letzt könnt Ihr natürlich noch die Farben der Balken bestimmen, um beispielsweise Eure Unternehmensfarben zu verwenden. Oder weil Ihr – wie ich – die Standardfarben einfach nicht so großartig findet. Ich gebe die Farbcodes hier als Variable `COLOR_SCHEMA` an, sodass ich sie nur einmal am Anfang des Skripts definieren und jederzeit schnell ändern kann.
COLOR_SCHEME <- c("#1B9E77","#D95F02","#7570B3","#E7298A","#66A61E","#E6AB02","#A6761D","#666666")Hier sind Input und Output im Detail gegenübergestellt. Wie Ihr sehen könnt, habe ich noch ein bisschen Text um den Plot gesetzt. Die Besonderheit ist, dass ihr in RMarkdown Code nicht nur innerhalb der Code-Chunks ausführen könnt, sondern kleine Code-Snippets auch innerhalb des Fließtextes. `r nrow(crawl)` zählt zum Beispiel die Zeilen des Crawls. Dadurch könnt ihr prinzipiell Text-Templates verwenden, innerhalb derer sich die Zahlen entsprechend der zugrundeliegenden Daten dynamisch ändern.

Interne Verlinkung in eine SQLite-Datenbank schreiben
Im obigen Plot sind nur acht URLs zu sehen, die mit `404` antworten. Trotzdem ist es natürlich immer von Interesse nachzusehen, woher diese URLs verlinkt werden – und vor allem mit welchem Ankertext. Denn ist dieser immer gleichlautend, kann man davon ausgehen, dass es sich um Template-Links handelt. Sie können also sehr schnell an einer Stelle behoben werden. Im Gegensatz zu Content-Links, die zumeist einzeln angepackt werden müssen. Ich möchte nun also die URLs des Crawls, die nicht erreichbar sind, mit den Link-gebenden Seiten aus dem `all_inliks`-Export des Screaming Frog zusammenführen.
Hinweis: Mir ist bewusst, dass Ihr auch einfach im `all_inlinks`-Export auf die `404`er filtern könntet. Ich brauche hier aber ein Beispiel, um Euch einen Join aus einer Datenbank zu veranschaulichen. Bitte entschuldigt also den kleinen Umweg.
Als erstes müsst ihr natürlich die `all_inlinks.csv` importieren. Das Verfahren kennt Ihr bereits.
all_inlinks <- read_csv("_data/all_inlinks_2019-02-05.csv", skip = 1) %>%
clean_names()
Der Report ist im vorliegenden Fall sehr klein.
> format(object.size(all_inlinks), units = "Mb") [1] "3.4 Mb"
Je nach Größe der Website kann der Report aber sehr schnell mehrere Millionen Zeilen und somit mehrere GigaByte groß sein. Da ich in meinen Analysen nur ad hoc auf ihn zurückgreife, möchte ich Ihn nicht die ganze Zeit im RAM vorhalten. Aus diesem Grund habe ich mir angewöhnt, ihn direkt in eine SQLite-Datenbank zu schreiben. Der große Komfortfaktor einer SQLite-Datenbank ist, dass Ihr – wie Ihr sofort sehen werdet – sie mit einer Zeile Code direkt auf Eurem Rechner initialisieren könnt. Ihr braucht also keinen Server, auf dem Ihr erst einmal eine Datenbank installieren müsst. Mit folgendem Code erstellt Ihr die Datenbank, wenn sie noch nicht vorhanden ist. Andernfalls verbindet Ihr Euch mit einer bestehenden.
con <- DBI::dbConnect(RSQLite::SQLite(), "all_inlinks.sqlite")
Als nächstes schreibt Ihr den DataFrame `all_inlinks` in die Datenbank. Auch das ist erneut denkbar einfach. Gibt es die Tabelle `inlinks` noch nicht in der Datenbank, wird sie automatisch erzeugt. Außerdem definiert Ihr, auf welchen Spalten in der Datenbank ein Index gebildet werden soll. Mit `rm()` löscht Ihr den DataFrame wieder aus dem RAM.
copy_to(dest = con,
df = all_inlinks,
name = "inlinks",
temporary = FALSE,
indexes = list("source",
"destination"))
rm(all_inlinks)
Anschließend muss die gerade in der Datenbank erstellte Tabelle natürlich referenziert werden, um Anfragen gegen sie zu fahren. Auch das ist ganz einfach und erfolgt durch dir folgende Code-Zeile.
inlinks <- tbl(con, "inlinks")
`inlinks` ist jetzt die Referenz. Referenz meint hier, dass hier wirklich nur eine Verbindung besteht. Es werden keine Daten nach R geladen. Das seht Ihr, wenn ihr die Referenz aufruft.
> inlinks # Source: table<inlinks> [?? x 9] # Database: sqlite 3.22.0 [E:\Dropbox # (Privat)\RStudio\campixx\all_inlinks.sqlite] type source destination size_bytes alt_text anchor status_code status <chr> <chr> <chr> <dbl> <chr> <chr> <dbl> <chr> 1 AHREF https~ https://ww~ 91896 NA Barf ~ 200 OK 2 AHREF https~ https://ww~ 91896 NA NA 200 OK 3 AHREF https~ https://ww~ 91896 NA NA 200 OK 4 AHREF https~ https://ww~ 91896 NA Barf ~ 200 OK 5 AHREF https~ https://ww~ 91896 NA NA 200 OK 6 AHREF https~ https://ww~ 91896 NA Barf ~ 200 OK 7 AHREF https~ https://ww~ 91896 NA NA 200 OK 8 AHREF https~ https://ww~ 91896 NA Start~ 200 OK 9 AHREF https~ https://ww~ 91896 NA Barf ~ 200 OK 10 AHREF https~ https://ww~ 91896 NA NA 200 OK # ... with more rows, and 1 more variable: follow <int>
`Source` und `Database` zeigen an, dass es sich hier tatsächlich um eine reine Datenbank-Tabelle handelt. Dass keine Daten nach R geladen werden, seht Ihr auch am `[?? x 9]`. Die Datenbank teilt Euch zwar mit, dass die Tabelle 9 Spalten hat. Allerdings ist zum jetzigen Zeitpunkt – da keine explizite Anfrage gegen die Datenbank besteht – nicht ermittelbar, wie viele Zeilen `(??)` in der Tabelle vorliegen.
Dieses Verhalten geht sogar so weit, dass selbst die Formulierung einer Anfrage nicht ausgeführt wird, solange dies nicht explizit von Euch gewünscht ist.
Bitte entschuldigt, wenn das gerade etwas nerdig ist. Aber das ist wirklich ein wahnsinnig komfortables Verhalten, wenn Ihr mit sehr großen Datenmengen bei begrenzten RAM-Ressourcen arbeiten müsst.
Wie müsst Ihr euch dieses Verhalten konkret vorstellen? Im Folgenden definiere ich eine Abfrage gegen die Datenbank. Es soll durchgezählt werden, wie häufig eine Seite intern verlinkt wird. Anschließend wird die Tabelle absteigend nach der Link-Zahl sortiert und dann nur die URLs geladen, die mehr als 200 Inlinks haben. Die Abfrage an sich wird in die Variable `top_linked_pages` geschrieben. Ruft Ihr die Abfrage auf, seht Ihr im Kopf der Antwort, dass es sich um eine `lazy query` handelt. Die Abfrage ist also faul, sie gibt nur ein paar Beispiel-Zeilen zurück, kennt aber nicht die Gesamtmenge (`[?? x 2]`), solange Ihr nicht explizit angebt (`collect()`), dass die Abfrage ausgeführt werden soll.
top_linked_pages <- inlinks %>%
count(destination) %>%
arrange(desc(n)) %>%
filter(n >= 200)
> top_linked_pages
# Source: lazy query [?? x 2]
# Database: sqlite 3.22.0 [E:\Dropbox
# (Privat)\RStudio\campixx\all_inlinks.sqlite]
# Ordered by: desc(n)
destination n
<chr> <int>
1 https://www.barf-alarm.de/blog/die-ersten-wochen-des-welpen-daheim/ 824
2 https://www.barf-alarm.de/blog/blutohr-beim-hund/ 779
3 https://www.barf-alarm.de/ 711
4 https://www.barf-alarm.de/produkt/gruenlippmuschelpulver-fuer-hunde/ 643
5 https://www.barf-alarm.de/blog/gastritis-chronisch-oder-akut-magensc~ 585
6 https://www.barf-alarm.de/bezahlmoeglichkeiten/ 551
7 https://www.barf-alarm.de/blog/laeufigkeit-bei-huendinnen-alles-was-~ 488
8 https://www.barf-alarm.de/blog/die-verschiedenen-modelle-der-rohfuet~ 464
9 https://www.barf-alarm.de/shop/barf-fleisch/ 453
10 https://www.barf-alarm.de/blog/wp-content/uploads/2016/11/xbarf-alar~ 444
# ... with more rows
> nrow(top_linked_pages)
[1] NA
> top_linked_pages %>%
+ collect() %>%
+ nrow()
[1] 68
Apropos Abfrage, Ihr seht kein SQL. Simple Abfragen können gänzlich mit R-Funktionen beschrieben werden, die dann automatisch in SQL übersetzt werden. Um Euch das SQL anzeigen zu lassen, könnt Ihr `show_query()` verwenden. Die SQL-Abfrage ist vielleicht nicht gerade elegant, erfüllt aber ihren Zweck.
> top_linked_pages %>% + show_query() <SQL> SELECT * FROM (SELECT * FROM (SELECT `destination`, COUNT() AS `n` FROM `inlinks` GROUP BY `destination`) ORDER BY `n` DESC) WHERE (`n` >= 200.0)
Jetzt aber zurück zur Ermittlung der Verlinkung der `404`er. Ihr habt jetzt alle internen Links in der Datenbank vorliegen und könnt Sie nun mit Eurem Crawl zusammenführen.
(not_found_urls <- crawl %>%
filter(status_code == 404) %>%
select(address) %>%
inner_join(inlinks,
by = c("address" = "destination"),
copy = TRUE) %>%
select(address, source))
write_csv(not_found_urls, "_exports/not_found_urls.csv")
Die resultierende Tabelle könnt Ihr Euch direkt im Analyse-Dokument ausgeben lassen. Sie bietet einige interaktive Elemente, indem sie bspw. eine Pagination darstellt, die Ihr klicken könnt. Um hier eine Handlung für die IT zu generieren, könnt Ihr die Tabelle natürlich direkt als CSV exportieren. Es gibt auch Packages, um eine Excel zu erzeugen. Der Einfachheit halber belasse ich es an dieser Stelle aber bei einer CSV.

Delta-Betrachtung eines alten und des aktuellen Crawls
Aufschlussreich ist es auch immer, zu sehen, welche Änderungen sich im zeitlichen Verlauf an einer Website ergeben haben. Hier wollen wir exemplarisch betrachten, welche Ressourcen nicht mehr, weiterhin oder neu verlinkt werden. Weitere denkbare Betrachtungsobjekte sind Title- und Description-Änderungen sowie Status-Code-Wechsel. Der Einfachheit halber gehe ich an dieser Stelle aber nur auf die Ressourcen ein. Das zugrundeliegende Verfahren könnt Ihr aber adaptieren.
Zunächst brauchen wir eine Funktion, die uns einen Indikator bereitstellt, ob eine Ressource nur im alten, nur im aktuellen oder in beiden Crawls vorkommt. R bietet von Haus aus keine solche Funktion, daher müssen wir eine eigene schreiben. Sie ist nicht sonderlich komplex, aber lang. Daher erspare ich Euch die Definition.
Hinweis: Die Funktion habe ich übrigens nicht selbst geschrieben, sondern von Stack Overflow übernommen. Ein weiterer großer Vorteil von R resp. programmatischer Analyse im Allgemeinen. Man muss nicht ständig das Rad neu erfinden. Deutlich klügere / erfahrenere Menschen als wir es sind, standen mit Sicherheit schon einmal vor den gleichen Problemen und haben sich Rat im Internet gesucht. Stack Overflow ist damit die reinste Fundgrube, an der Ihr Euch scharmlos bedienen könnt und solltet.
Mit folgendem Code legt ihr die beiden Crawls übereinander und erhaltet als Resultat eine Tabelle mit Flag-Spalte.
diff_crawls <- full_join_indicator(crawl_old %>%
select(address, content_type, seg_seitenbereich),
crawl %>%
select(address, content_type, seg_seitenbereich),
by = c("address", "content_type", "seg_seitenbereich"),
indicator = c("nicht_laenger_verlinkt", "neu_verlinkt", "identisch"))

Diese Tabelle gebt Ihr wiederum an eine Plotting-Funktion.
diff_crawls %>%
count(join_indicator, content_type, seg_seitenbereich) %>%
ggplot(aes(join_indicator, n, fill = join_indicator)) +
geom_col() +
facet_grid(~content_type) +
guides(fill = F) +
scale_fill_manual(values = COLOR_SCHEME) +
theme_light() +
theme(axis.text.x = element_text(angle = 45, hjust = 1),
plot.title = element_text(face = "bold"),
plot.subtitle = element_text(color = "#666666"),
plot.caption = element_text(color = "#AAAAAA", size = 10)) +
labs(title = "Delta-Betrachtung",
subtitle = "2018-10-25 vs. 2019-02-05",
x = "",
y = "Anzahl URLs",
caption = paste0("Stand: ", Sys.Date()))
Anhand des resultierenden Plots können wir sehr leicht Veränderungen an den Mengengerüsten der Ressourcen erkennen. Hier sind offensichtlich verhältnismäßig viele HTML-, Bilder- und JS-Ressourcen entfallen. Ein genauer Blick in die Daten würde uns zeigen, dass die AMP-Variante der Website deaktiviert wurde.

Daten aus Google Analytics mittels API-Abfragen beschaffen
Fast geschafft! Zu guter Letzte möchte ich Euch noch zeigen, wie Ihr auch externe Datenquellen in Eure Analyse integrieren könnt. Exemplarisch möchte ich dies für Google-Analytics-Daten (GA) machen. Im Grunde kann aber jede Quelle, die eine API bereitstellt, hinzugezogen werden. Denkbar sind bspw. auch die Google Search Console oder Sistrix.
Hinweis: Und Ihr seid nicht einmal auf Datenquellen mit API beschränkt. Selbst Web Scraping könnt Ihr mit R verwirklichen. Allerdings muss ich zugeben, dass dazu Python deutlich komfortabler ist.
Für GA gibt es dankbarerweise ein Package – googleAnalyticsR. Vom gleichen Autor, Mark Edmondson, gibt es auch noch Packages für die Authentifizierung (googleAuthR), welches wir auch verwenden werden, und die Google Search Console (searchConsoleR).
Zunächst müsst Ihr natürlich die benötigten Packages laden.
library(googleAnalyticsR) library(googleAuthR)
Anschließend müsst Ihr über `options()` Eure API-Credentials angeben, die Ihr in der Google Cloud Platform generieren könnt, und dem Skript die Berechtigung für Euren Google-Account erteilen.
options(googleAuthR.client_id = "XXX-XXX.apps.googleusercontent.com",
googleAuthR.client_secret = "XXX",
googleAuthR.scopes.selected = "https://www.googleapis.com/auth/analytics.readonly")
gar_auth()
`gar_auth()` wird beim ersten Ausführen Euren Browser öffnen, in dem Ihr den Skript-Zugriff bestätigt. Dadurch wird eine Authentifizierungsdatei erzeugt. Fortan müsst Ihr diesen manuellen Schritt also nicht mehr durchführen.
Hinweis: Damit steht im Übrigen einer automatischen Report-Erstellung auch nichts mehr im Wege! Holt Euch wöchentlich die aktuellen Daten, schreibt sie in einer Datenbank und generiert einmal in der Woche mittels RMarkdown einen automatischen Report, den Ihr Euch per Mail zuschicken lasst.
Nachdem die Authentifizierung durchgeführt wurde, könnt Ihr Euch die GA-Properties anzeigen lassen, um die benötigte `viewID` der anzufragenden Datensicht zu ermitteln.
> ga_account_list() %>% + View()
Die Abfrage gegen die API sieht dann wie folgt aus.
ga_data <- google_analytics(viewId = "XXX",
date_range = c("2018-01-01", "2018-12-31"),
metrics = "pageviews",
dimensions = "pagePath",
anti_sample = TRUE)
Ihr definiert den abzufragenden Berichtszeitraum sowie die Kombination aus Metriken und Dimensionen. Großer Vorteil des Packages ist, dass es, wenn Ihr `anti_sample` auf `TRUE` gesetzt habt, überprüft, ob in der API-Antwort ein Sampling vorhanden ist. Sollte dies der Fall sein, bricht das Package die Anfrage automatisch in möglichst granulare Anfragen herunter, um das Sampling zu umgehen.
Die GA-Daten liegen nun in R vor. Um sie mit den Crawl-Daten zusammenführen zu können, muss noch kurz die Domain an den `pagePath` geschrieben werden.
ga_data <- ga_data %>%
mutate(address = paste0("https://www.barf-alarm.de", pagePath))
Wir wollen uns nun im Detail angucken, ob Seiten unserer Website, die viele Page Views erhalten – also aus Nutzersicht stark nachgefragt werden – intern auch stark verlinkt sind – wir sie somit ebenfalls als bedeutsam erachten. Das ist ein klassischer Abgleich der Eigen- und Außenwahrnehmung unserer Webpages. Dazu joint Ihr die beiden DataFrames `crawl` und `ga_data`.
pageviews_vs_linkscore <- crawl %>%
select(address, link_score, seg_seitenbereich) %>%
inner_join(ga_data,
by = "address")
Anschließend plotten wir wieder den DataFrame.
ggplot(pageviews_vs_linkscore, aes(pageviews, link_score, color = seg_seitenbereich)) +
geom_point(alpha = .7, size = 4) +
theme_light() +
labs(title = "Eigen- vs. Fremdwahrnehmung",
subtitle = "Sind meine meist verlinkten Seiten auch die am häufigs-ten besuchten Seiten?",
x = "Page Views (log10)",
y = "Internal Link Score",
color = "Seitenbereich",
caption = paste0("Stand: ", Sys.Date())) +
theme(plot.title = element_text(face = "bold"),
plot.subtitle = element_text(color = "#666666"),
plot.caption = element_text(color = "#AAAAAA", size = 10)) +
scale_x_log10(labels = scales::comma_format(big.mark = ".", decimal.mark = "."))

Fazit
Und damit sind wir wieder beim Plot, der diesen Beitrag eingeleitet hat. Ich hoffe, ich konnte Euch einen ersten „kleinen“ Einblick in die Potenziale der Daten-Analyse mittels R bieten. Wenn Ihr es bis hierin geschafft habt, habt Ihr bereits viel gesehen und gelernt. Ich habe Euch gezeigt, wie Ihr mittels RMarkdown reproduzierbare Analyse-Dokumente erstellen könnt, die jederzeit nachvollziehbar sind, da der Code erhalten bleibt und sich somit selbst dokumentiert. Wir sind die verschiedenen Phasen eines Analyse-Prozesses durchlaufen, vom Import der Daten, über die Aufbereitung und Anreicherung der Daten, hin zur Transformation und Visualisierung. Ihr habt mit `janitor` ein Package kennengelernt, mit dem Ihr Euch on-the-fly einen Einblick in die Datenbasis verschaffen könnt. Darüber hinaus habt Ihr das grundlegende Konzept der Datenvisualisierung in R mittels `ggplot()` gesehen. Ihr habt eine SQLite-Datenbank initialisiert, um darin die interne Verlinkung zu speichern, sodass Ihr sie nicht im RAM vorhalten müsst. Um der zeitlichen Dimension Rechnung zu tragen, haben wir zwei Crawls übereinandergelegt, um Unterschiede zu ermitteln. Zum Schluss habt Ihr erfahren, wie Ihr Externe Datenquellen wie die Google-Analytics-API anzapfen könnt, um Eure Crawl-Daten anzureichern.
Wenn Ihr Lust auf R bekommen habt, möchte ich Euch noch einmal das Buch R for Data Science von Hadley Wickham wärmstens ans Herz legen – und ja, ich habe schamlos, nein, in ehrfürchtiger Devoation den Titels seines Buches adaptiert. Mir ist bewusst, dass der Einstieg in R nicht gerade einfach ist. Insbesondere wenn man bisher keine Erfahrung mit Programmierung hat. Aber lasst Euch gesagt sein, die hatte ich am Anfang auch nicht. Und ich habe es nicht bereut, Zeit ins Erlernen zu investieren. Auf lange Sicht lohnt es sich wirklich. Das folgende Diagramm veranschaulicht das sehr schön. Am Anfang ist die Lernkurve für R sehr steil. Da seid Ihr mit Excel deutlich schneller. Je komplexer die Aufgaben jedoch werden, desto weniger schwierig wird ihre Lösung mit R, während bei Excel die Schwierigkeit signifikant zunimmt.

Um Euch bei Euren ersten Schritten nicht allein zu lassen, möchte ich Euch ermuntern, der Gruppe OmPyR auf Facebook beizutreten, die mein Kollege Johannes Kunze und ich gegründet haben. Wir möchten Daten-Analysen mittels R, Python, KNIME aber auch Excel stärker in der Online-Marketing-Community verankern. Dazu wollen wir eine Plattform für den Austausch etablieren – denn aller Anfang ist schwer! Wir hätten uns in unserer Anfangszeit eine solche Gruppe sehr gewünscht und möchten Euch jetzt die Möglichkeit bieten, von unseren – aber auch den Erfahrungen der Community – zu profitieren, um den Einstieg so einfach wie möglich zu gestalten.
Also, ich hoffe, man liest sich. Bis dahin, happy R! 👋

Patrick Lürwer
Senior-Analyst & Partner
In meinem Studium des Bibliotheksmanagements habe ich mich von Anfang an mehr für die Metadaten als für die Bücher interessiert. Meine Leidenschaft für Daten — das Erfassen, Aufbereiten und Analysieren — habe ich anschließend durch mein Master-Studium der Informationswissenschaft weiter ausleben und vertiefen können. Bei get:traction kombiniere ich meine Data-Hacking-Skills und meine Online-Marketing-Expertise, um datengestützte Empfehlungen für Kunden zu formulieren und umgesetzte Maßnahmen zu messen. Mein Hauptaufgabenbereich liegt dabei in der Analyse von Crawls, Logfiles und Tracking-Daten, der Konzeption von Informationsarchitekturen und der Anreicherung von Webinhalten mittels semantischer Auszeichnungen.




2 Kommentare:
[…] Patrick Lürwer lieferte in seiner Session einen kurzen Überblick darüber, wie sich im Workflow mit Screaming Frog, der Google Search Console, R und RMarkdown reproduzierbare Analysen erstellen lassen. Dabei beleuchtete er den gesamten Prozess von Import und Normalisierung der Daten über die Verarbeitung mit RStudio bis zum Export als PDF. Wer keine Excel Tabellen mehr sehen kann, sollte den Sprung in die R Community erwägen. Patricks überzeugenden Vortrag gibt es bei gettraction. […]
[…] Patrick Lürwer lieferte in seiner Session einen kurzen Überblick darüber, wie sich im Workflow mit Screaming Frog, der Google Search Console, R und RMarkdown reproduzierbare Analysen erstellen lassen. Dabei beleuchtete er den gesamten Prozess von Import und Normalisierung der Daten über die Verarbeitung mit RStudio bis zum Export als PDF. Wer keine Excel Tabellen mehr sehen kann, sollte den Sprung in die R Community erwägen. Patricks überzeugenden Vortrag gibt es bei gettraction. […]