
Es war wieder einmal SEOkomm. Im Jahr 2019 war ich nicht nur Gast, sondern durfte, zusammen mit Sabine Langmann, auf die große Bühne. Leider hat in 30 Minuten Vortrag bei weitem nicht alles hineingepasst. Für alle die im Vortrag waren, oder auf anderem Wege hierher gefunden haben, gibt’s in diesem Blogbeitrag noch einmal alle Infos! Den Teil von Sabine Langmann zu unserem SEOkomm 2019 Vortrag findest du in ihrem Blog unter https://www.sabine-langmann.com/.
Den ScreamingFrog automatisch für mehrere Projekte starten und einen Export generieren… die Exporte des ScreamingFrog einlesen, säubern und im Anschluss in Google BigQuery speichern – Vor diese Herausforderung habe ich mich für die diesjährige SEOkomm gestellt. Eine zusätzliche Bedingung war jedoch: Kein Programmcode! Normalerweise wäre schließlich Python das Werkzeug meiner Wahl. Da Quellcode aber häufig abschreckt und mir wichtig war, dass es jeder nachbauen kann, habe ich mich entschieden den ETL Prozess in KNIME zu realisieren.
Neben den Standard-Daten die der ScreamingFrog liefert, wurden zusätzlich weitere Werte per „Custom Extraction“ durch den Crawler erfasst. In Sabines Blogartikel zur Custom Extraction, Xpath und allem was dazugehört bekommt ihr alle Infos zum ersten Teil des Talks.
Was lerne ich hier & was brauche ich dafür?
Im Grunde benötigt ihr nicht viel. Ganz wichtig ist neben ein paar Tools jedoch, dass ihr Lust habt etwas zu basteln und keine Angst habt etwas kaputt zu machen. Und wenn es Fragen gibt: Schreibt mir gerne einen Kommentar oder kontaktiert mich direkt.
Benötigte Tools: ScreamingFrog (v12+), KNIME (v4+), BigQuery, BigQuery-Befehlszeilentool, Simba-Treiber für BigQuery (4.2)
Hinweis: BigQuery ist nicht kostenlos. Es gibt Jedoch für alle die mit der Google Cloud experimentieren wollen einen „Free Tier“ von 300$. Außerdem bietet jedes der Google Cloud Produkte ein monatlich erneuertes freies Kontingent.
Wenn ihr es euch nun zur Aufgabe macht, meinen Prozess nachzubauen, werdet ihr auf dem Weg die folgenden Dinge lernen:
- Steuere den ScreamingFrog per Kommandozeile oder Batch-Datei.
- Nutze KNIME, um die generierten Exporte einzulesen und zu säubern, sodass mit den Daten gearbeitet werden kann.
- Spiele die Daten – ebenfalls mit KNIME – in Google BigQuery.
- Starte die Abläufe automatisch mittels Windows Aufgabenplaner.
- Frage Google BigQuery mit KNIME ab und beantworte deine Fragen.
Wenn ihr das Projekt SEOkomm2019 von Github herunterladet, befinden sich darin folgende Dateien, bzw. diese Struktur (von oben nach unten):

- bq_logs: Log-Dateien des BigQuery Uploads
- knime_cleaned: Temporäre Dateien zum Upload und JSON-Schemas für BigQuery Tabellen
- knime_loaded: „Archiv“ für Crawls die in BigQuery geladen sind
- sf_configs: ScreamingFrog Konfigurationsdateien
- sf_exports: Export-Ordner der Crawls
- sf_logs: Log-Dateien der Crawls
- crawl_fahrrad.bat: Beispiel Batch Datei zum Crawl der Fahrrad.de E-Bike Kategorie
- etl_fahrrad.bat: Beispiel Batch Datei zum Ausführen des KNIME Workflows
Zur Vorbereitung des Vortrags auf der SEOkomm2019 wurden drei Seiten regelmäßig gecrawlt. Diese waren gourmondo.de, geschenke24.de und fahrrad.de. Im weiteren Verlauf zeige ich euch alles am Beispiel von fahrrad.de.
ScreamingFrog per Batch-Datei steuern
Seit der Version 10 des ScreamingFrog gibt es die Möglichkeit, diesen per Kommandozeile zu steuern. Das bedeutet, ihr müsst ScreamingFrog nicht komplett mit Interface und allem Drum und Dran starten. Vielmehr könnt ihr durch einfache Befehle im Terminal einen Crawl starten, kontrollieren was exportiert und wohin der Export am Ende gespeichert wird. Hier findet ihr eine Übersicht aller Befehle für den ScreamingFrog.
Hinweis: In der Anleitung auf ScreamingFrog.co.uk wird im Terminal zunächst der Pfad gewechselt, sodass man sich im Verzeichnis des Froschs befindet. Hier liegt nämlich die ScreamingFrogSEOSpiderCli.exe, die man benötigt. Damit man dies nicht jedes Mal machen muss, könnt ihr den Pfad einfach in euren „PATH“ eintragen. Dann kennt Windows den Befehl ohne den Pfad zu wechseln.
Geht dazu wie folgt vor:
1. „Windowstaste + R“ drücken um „Ausführen“ zu öffnen.
2. „Systemumgebungsvariablen bearbeiten“ eingeben und aufrufen.
3. „Umgebungsvariablen“ anklicken
4. Im oberen Feld „Benutzervariablen für [Nutzername]“ die Variable „Path“ suchen und „Bearbeiten“.
5. „Neu“ anwählen und den Frosch-Pfad eintragen. Bei mir z.B.: „C:\Program Files (x86)\Screaming Frog SEO Spider“
Wenn wir die Befehle in eine Batch-Datei schreiben, können wir den ScreamingFrog nicht nur per Kommandozeile steuern, wir können die erstellte Datei auch einfach per Doppelklick ausführen. Außerdem, wie in unserem Fall, ist es nun auch ganz einfach, die Datei in den Windows Aufgabenplaner zu hängen und automatisch zu starten.
Warum nicht das Scheduling in ScreamingFrog nutzen?
Der ScreamingFrog bringt ebenfalls eine eigene Funktion zum „Scheduling“ mit. Da wir jedoch im Windows Aufgabenplaner mehrere Tasks hintereinander ausführen, wurde der Weg per Batch-Datei gewählt.
So eine Batch-Datei, oder auch Bat-Datei ist dabei relativ simpel zu erstellen. Es handelt sich dabei um eine simpele Text-Datei die auf „.bat“ endet. Der Inhalt unserer Batch-Datei „crawl_fahrrad.bat“ sieht nun wie folgt aus:
ScreamingFrogSEOSpiderCli.exe --crawl "https://www.fahrrad.de/fahrraeder/e-bikes/" --config "sf_configs/Fahrrad_Ebike_Products_Crawl.seospiderconfig" --output-folder "sf_exports/fahrrad" --export-format csv --export-tabs "Internal:All" --timestamped-output --project-name seokomm2019 --task-name fahhrad --headless >> "sf_logs/fahrrad_%DATE%.logDie einzelnen Angaben sind relativ selbsterklärend. Auf die weniger klaren gehe ich kurz ein:
- –timestamped-output
- Wenn vorhanden, werden alle Exporte in eigene Ordner geschrieben deren Name aus Datum und Zeitpunkt besteht.
- –project-name / –task-name
- Seit Version 12 können Crawls die in der ScreamingFrog Datenbank gespeichert werden in Projekte aufgeteilt werden. Jeder Crawl in diesem Projekt ist ein Task. Dies kann man hiermit angeben.
- –headless
- Das ScreamingFrog Interface startet nicht.
- >> „sf_logs/fahrrad_%DATE%.log“
- Kein Frosch-Befehl. Dies bewirkt, das die Ausgabe des Terminals in eine Datei geschrieben wird. Da „%DATE% im Dateinamen steht, gibt es jeden Tag eine neue Datei.
- Warum? Damit wir, wenn einmal etwas nicht klappt, nachlesen können was schief gelaufen ist.
Habt ihr nun den Pfad zur ScreamingFrogSEOSpiderCli.exe in euren Windows-Path eingefügt und eine Batch-Datei erstellt (oder die vorhandene verwendet), solltet ihr euren Crawl einfach per Doppelklick auf die Datei ausführen können.
ScreamingFrog per Windows Aufgabenplaner starten
Damit unsere Batch-Datei automatisch ausgeführt wird, hängen wir diese in den Windows Aufgabenplaner. Diesen startet ihr zum Beispiel in dem ihr die Windows-Taste drückt und dort „Aufgabenplaner“ eingebt.
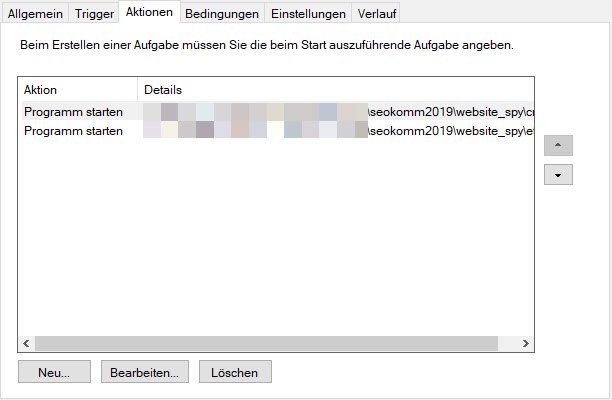
Hier könnt ihr nun ganz einfach unter „Aktion“ → „Aufgabe erstellen“ eine neue Aufgabe erstellen. Ich empfehle euch jedoch dringend: legt Ordner an, um eure Aufgaben zu sortieren! Euer Zukunfts-Ich wird es euch danken.
Den Task anzulegen ist recht simpel. Ihr müsst der Aufgabe nur einen Namen geben, entscheiden wann der Task ausgeführt wird und natürlich festlegen was ausgeführt werden soll. Ich habe euch die wichtigsten Einstellungen hier als Screenshots eingefügt.
-

Allgemein: Name & ohne Anmeldung ausführen -
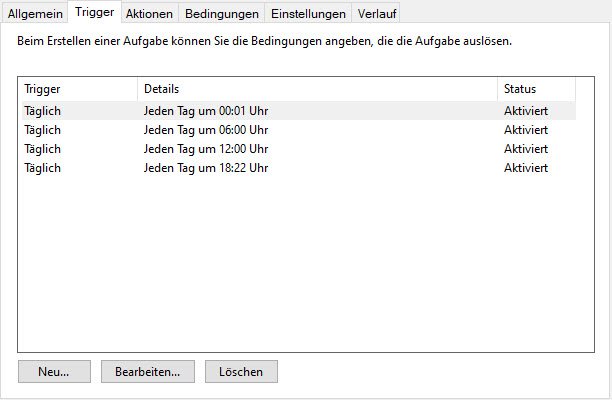
Trigger: Wann wird der Task ausgeführt -

Aktion: Was wird ausgeführt

Im Punkt „Aktion bearbeiten“ gebt ihr bei „Programm/Script“ einfach den vollständigen Pfad zu der Batch-Datei an.
„E:\…\seokomm2019\website_spy\crawl_fahrrad.bat“
Im Feld „Starten in“ den Ordner zu dem Projekt. Das ist wichtig, da wir relative Pfade verwendet haben, die sonst nicht funktionieren.
„E:\…\seokomm2019\website_spy“
Du bist hier angekommen und dein Crawl läuft automatisch, von selbst, exportiert Daten als CSV… du musst nichts mehr dafür tun? Fantastisch! 😀🤜🤛😁 Aber wir sind ja noch nicht fertig. Also hol dir einen ☕ und ab in die nächste Runde 🔔. Den Crawl mit KNIME bearbeiten und in BigQuery speichern. 😎👍
ScreamingFrog Crawl in KNIME einlesen, bearbeiten und in BigQuery laden
Eins muss ich vorweg sagen: Ich kann euch im Rahmen dieses Artikels KNIME leider nicht erklären. Wir steigen also direkt voll ein.
Aber es gibt auch gute Nachrichten: KNIME ist nicht kompliziert! Im Grunde ist es ein riesiges Puzzle an Funktionen die ihr richtig zusammensetzen müsst.
Und noch mehr gute News: Auf unserem Blog findet ihr KNIME Artikel und wir bieten KNIME-Schulungen an!
KNIME Artikel & Downloads
KNIME für Anfänger
KNIME Knoten Cheat Sheet
Infos zur get:traction KNIME Schulung
KNIME Schulung für SEO
→ Oder direkt Kontakt aufnahmen unter KNIME@gettraction.de
Hier seht ihr nun den Workflow, der die ganze Arbeit macht. In den folgenden Abschnitten zeige ich euch kurz, wofür die einzelnen Teile des Workflows zuständig sind.
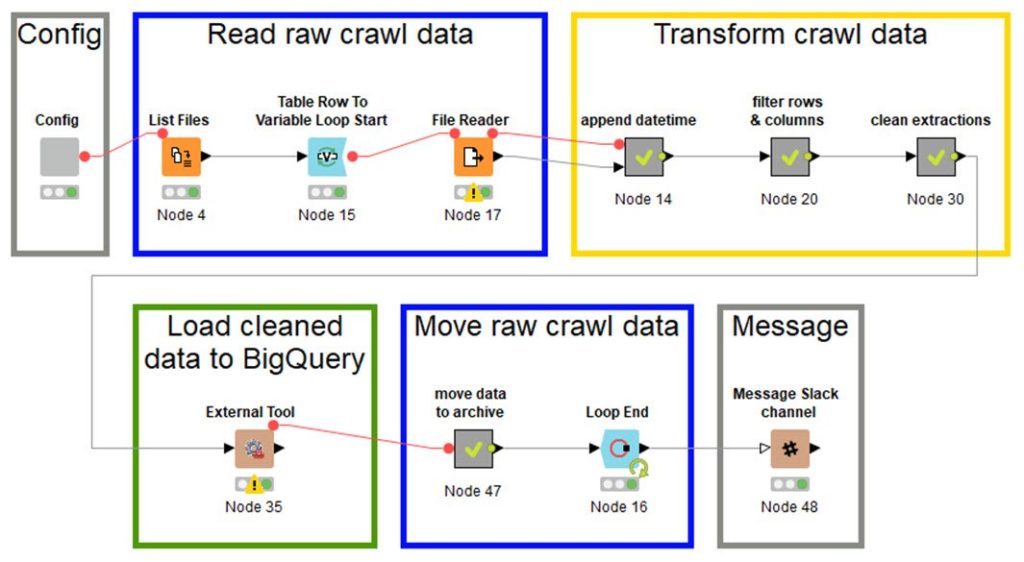
Hinweis: Wenn ihr den Workflow wirklich ausführen wollt und nicht das Beispiel von fahrrad.de nutzt, müsst ihr die Projekt-Unterordner (Ordner „fahrrad“ in „sf_exports“, „knime_cleand“ und „knime_loaded“) per Hand anlegen. Das gleiche gilt für den Datensatz in Google BigQuery.
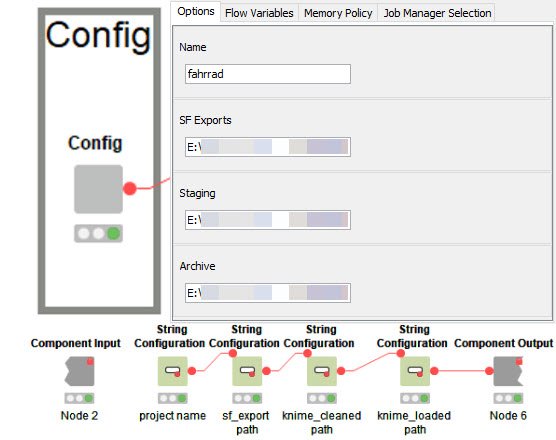
Konfiguration
Ich habe es mir angewöhnt KNIME Workflows über eine Konfig-Komponente zu steuern. Das sind mehrere Knoten (wie hier im Bild zu sehen), die zu einer Komponente zusammengefügt wurden (Rechtsklick + „Create Component“).
Wenn in der Komponente Eingabe-Knoten vorhanden sind, kann der neu entstandene Knoten mit Rechtsklick + „Configure“ (F6) konfiguriert werden. Falls du einen KNIME Server hast, erscheinen diese Eingabemöglichkeiten im Webportal (aber das führt jetzt etwas zu weit 😉).
Tipp: Beschäftigt euch mit den Komponenten!
Man kann hiermit verdammt viel anstellen.
→ Eigenständige Knoten die eine komplette Beschreibung der Funktion, sowie der Eingabe- und Ausgabeports mit sich tragen.
→ Ausgabe von mehreren Diagrammen, die sich über einen Editor einfach anordnen lassen.
→ Teilen der Komponenten mit Kollegen und vieles mehr!
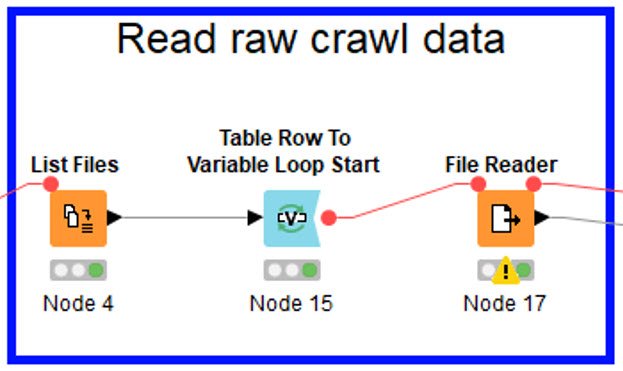
Crawls in KNIME einlesen
Der zweite Part listet alle CSV-Dateien auf die im angegebenen Ordner vorhanden sind. Der Pfad hierfür kommt aus der vorherigen Komponente (SF Exports).
Diese Liste an CSV-Dateien wird im nun startenden Loop abgearbeitet. Dabei wird jeweils eine Datei vom File Reader eingelesen. Der Loop „verrät“ dem File Reader dabei welche Datei an der Reihe ist.

Crawls in KNIME bereinigen
Nun folgen drei Meta-Knoten. Diese fassen ebenfalls mehrere Knoten in sich zusammen. Im Gegensatz zu den Komponenten machen sie aber auch nicht mehr. Auf zwei der Knoten gehe ich kurz ein.
„append datetime“
Da wir mehrere Crawls abspeichern und diese natürlich auf ihren Zeitstempel filtern werden, benötigt jeder Datensatz einen Zeitstempel. Erinnert ihr euch an das SF Kommando „timestamped-output“? Genau diesen Zeitstempel, also den Namen des Ordners indem der Export liegt, verwenden wir nun als neue Spalte in unseren Daten.

„clean extractions“
Hier passiert nun die Bereinigung der Informationen aus den ScreamingFrog „Custom extractions“. In den Beispielen der SEOkomm2019 haben wir vor allem Preisinformationen extrahiert. Diese beinhalten natürlich Zeichen wie „€“ und „%“ und werden somit nur als Strings eingelesen, nicht als Zahlen.
Mittels einfachen RegExp Befehlen im „Column Expresseion“ Knoten lassen sich die Zahlen extrahieren. Diese werden im Anschluss einfach von Strings in „echte“ Zahlen umgewandelt, damit man mit ihnen arbeiten und rechnen kann.
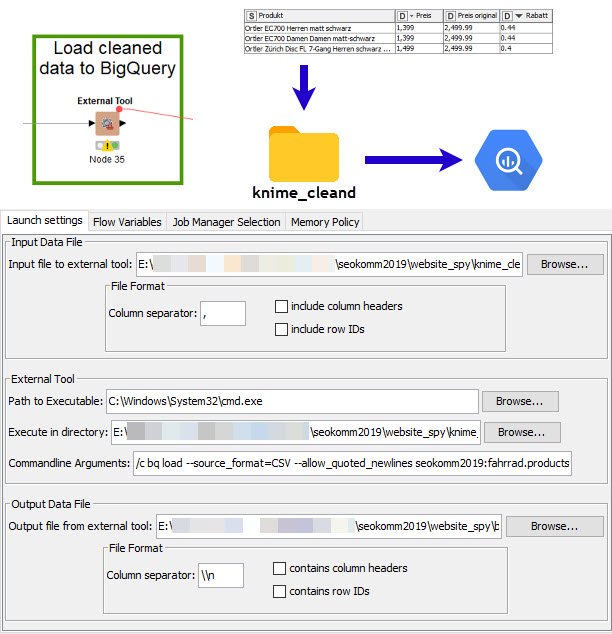
ScreamingFrog Crawl mit KNIME in BigQuery laden
Habt ihr bereits das BigQuery-Befehlszeilentool (bq) installiert und konfiguriert? Wir benutzen es jetzt!
Hier passiert nun die ganze Magie. Wir laden die Daten in BigQuery! Mit dem „External Tool“ Knoten führen wir den Befehl bq load mit dem bq-Tool aus. Dieser lädt eine CSV-Datei in eine Tabelle.
Was passiert hier genau? Der Knoten speichert die Daten der Tabelle in eine temporäre Datei, die bei jedem Vorgang überschrieben wird. Ausgeführt wird was im Bereich „External Tool“ angegeben wird. In unserem Fall die Windows Kommandozeile. Diese führt dann einfach das bq-Kommando aus, das in „Commandline Arguments“ angegeben ist.
So sieht der bq-Befehl im Ganzen aus. Dabei gibt man mit load an das Daten geladen werden. Natürlich muss man per Parameter mitteilen, um welchen Dateityp es sich handelt (CSV, JSON, etc) und wie die Datei aufgebaut ist. Wichtig ist, dass ihr den korrekten Datensatz angebt. Hier ist es seokomm2019.fahrrad.products, wobei seokomm2019 das Projekt ist, fahrrad der Datensatz und products die Tabelle (Projekt und Datensatz müsst ihr leider händisch anlegen).
bq load --source_format=CSV --allow_quoted_newlines seokomm2019:fahrrad.products cleaned_file.csv schema.json >> "E:\\...\\seokomm2019\\website_spy\\bq_logs\\fahrrad.log" 2>&1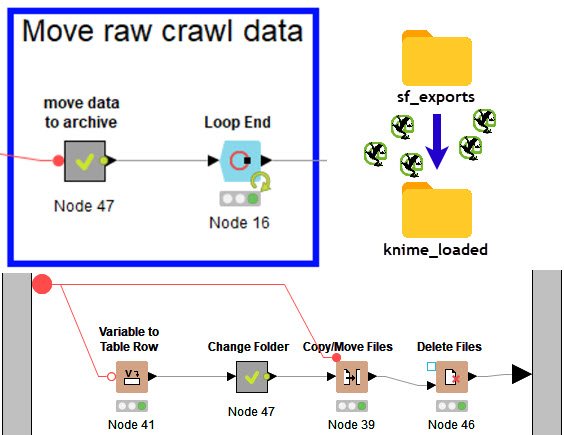
Dateien mit KNIME verschieben
KNIME bietet viele Möglichkeiten mit Dateien zu arbeiten. Diese können verschoben, kopiert, gelöscht oder umbenannt werden. Dabei funktioniert das sowohl lokal, als auch auf FTP Servern oder zum Beispiel Amazon S3 Buckets.
Wir verschieben im Workflow lokal die Exporte des ScreamingFrog in den Ordner „knime_loaded“. Dieses dient als ein Archiv aller importierten Daten.
Solltet ihr eure BigQuery Tabelle neu erstellen müssen, da ihr z.B. den KNIME Workflow angepasst habt, kopiert ihr einfach alle CSV Dateien aus „knime_loaded“ zurück in „sf_exports“ und lasst KNIME einfach für euch arbeiten.
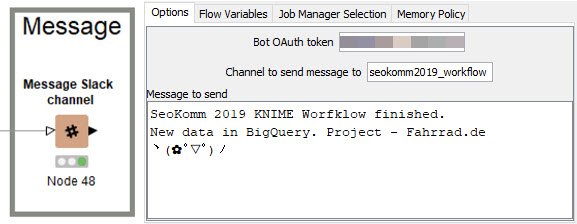
Slack Nachricht mit KNIME schicken
Für den Slack Knoten in KNIME benötigst du einen OAuth Token. Hier findest du alle Infos zu den Tokens. Wenn du den Token hast, kannst du ganz einfach Nachrichten an einen Slack Channel schicken. In diesem Workflow gebe ich mir selbst Bescheid, dass der Workflow gelaufen ist.
KNIME per Batch-Datei steuern
KNIME bietet, so wie ScreamingFrog, die Möglichkeit per Kommandozeile ausgeführt zu werden. Daher können wir auch wieder eine simple BAT-Datei schreiben, die unseren ETL-Prozess ausführt. Wichtig ist dabei -reset, damit der Workflow jedes mal zurückgesetzt wird und -nosave, da der Workflow nicht gespeichert werden muss.
cd "C:\Program Files\KNIME"
knime -consoleLog -nosplash -nosave -reset -application org.knime.product.KNIME_BATCH_APPLICATION -workflowDir="E:\02_analytics\01_Knime\Workflows\seokomm2019\etl_fahrrad"KNIME per Windows Aufgabenplaner starten
Da wir ja bereits einen Task im Aufgabenplaner für den ScreamingFrog Crawl angelegt haben, muss nun nur noch ein weiterer Task in den bereits bestehenden Ablauf eingefügt werden. Die KNIME Batch-Datei also einfach nach der Frosch Batch-Datei einhängen. So eingestellt läuft nach Abschluss des Crawls direkt der KNIME Workflow ab, liest den Crawl Export ein, bereinigt ihn und schreibt ihn in Google BigQuery.
Das war es auch schon mit dem KNIME Workflow 😎. Klasse, dass du noch hier bist! Ich hoffe es gab nicht allzu viele Momente bei denen du dir die Haare gerauft hast (╯°□°)╯︵ ┻━┻…
Wenn du weiter dran bleibst, zeige ich dir wie du mit KNIME Daten aus Google BigQuery abfragst.
Google BigQuery mit KNIME abfragen
Bevor wir mit KNIME Daten aus BigQuery abfragen können, müssen wir etwas Vorarbeit leisten. Es gibt leider noch keinen nativen Knoten, um mit Google BigQuery zu kommunizieren. Aber im KNIME Forum liest man zumindest, dass das KNIME-Team bereits an so etwas arbeitet.
Eben noch habe ich geschrieben, dass es keine nativen Knoten gibt und schon kann ich meine Aussage wieder revidieren. Die neue Version KNIME 4.1 ist veröffentlicht worden. Dort gibt es nun Knoten für Google Big Query.
We plan to have a dedicated Big Query Connector for the new DB framework in once of the next releases which will fix this issue and will make working with BigQuery within KNIME Analytics Platform easier.
https://forum.knime.com/t/knime-labs-db-nodes-bigquery-db-query-readers-dont-work/15482/4
Wie zu Beginn beschrieben, benötigen wir den Simba-Treiber für BigQuery. Google stellt ihn direkt zur Verfügung. Ich habe Version 4.2 benutzt. Ihr ladet ein Zip-Archiv herunter. Dieses muss im nächsten Schritt entpackt werden, wohin ist dabei eigentlich egal. Ich habe mir angewöhnt solche Treiber die ich in KNIME benutze an einem Ort zu sammeln.
Nun müsst ihr in den KNIME Einstellungen die Datenbankverbindung samt Treiber hinterlegen. Zu den Einstellungen findet ihr unter „File“→“Preferences“→“KNIME“→“Databases“.
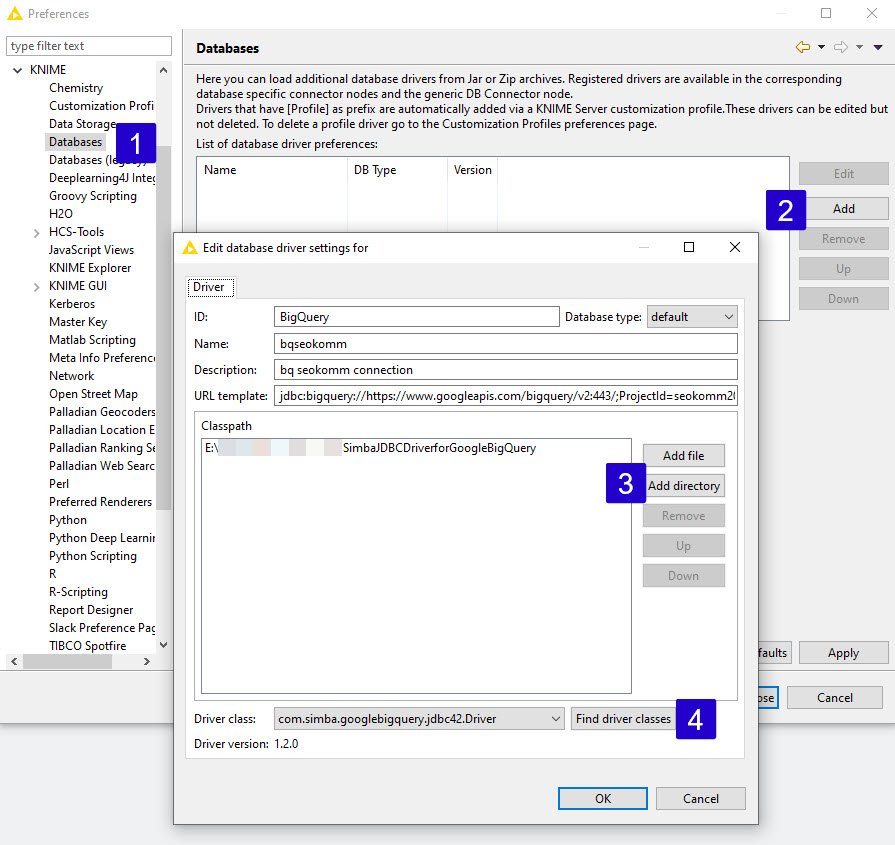
Google BigQuery Datenbankverbindung in KNIME erstellen
- Punkt Datenbanken auswählen.
- „Add“ auswählen, um neue Verbindung zu erstellen
- „Add directory“ auswählen und den entpackten Ordner angeben.
- „Find driver classes“ auswählen. Nun sollte der Treiber automatisch ausgewählt sein.
Ist das geschafft, müssen die restlichen Felder einfach ausgefüllt werden. Das „URL template“ ist bei mir wie folgt vergeben:
jdbc:bigquery://https://www.googleapis.com/bigquery/v2:443/;ProjectId=seokomm2019;OAuthType=1
Im Anschluss alles mit „OK“ bestätigen und die Einstellungen speichern.
SEO Monitoring: Veränderte Title aus Google BigQuery mit KNIME abfragen
Da KNIME nun mit Google BigQuery kommunizieren kann, sind die KNIME Datenbank-Knoten wie gewohnt einsetzbar. Aber was tun wir nun damit?
Ein nützlicher und sehr simpler Fall im SEO Monitoring besteht darin, Crawls miteinander zu vergleichen. Da wir ScreamingFrog Crawls mit Zeitstempeln in Google BigQuery gespeichert haben, ist es ein leichtes zwei dieser Datensätze aufeinanderzulegen. In diesem simplen Beispiel interessiert uns, welche Title sich zwischen den beiden Crawls geändert haben. Die Antwort ist nur einen SQL entfernt!
select latest.address,
latest.title_1 as new_title,
earliest.title_1 as old_title
from (
select address, title_1
from seokomm2019.fahrrad.products
where datetime = '2019-11-05T18:22:08'
) latest
inner join
(
select address, title_1
from seokomm2019.fahrrad.products
where datetime = '2019-10-30T15:46:25'
) earliest
on earliest.address = latest.address
and earliest.title_1 <> latest.title_1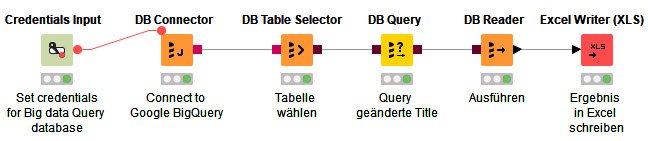
In KNIME sieht ein simpler Workflow für eine Abfrage aus wie im Screenshot zu sehen (auch als Export im Download auf Github).
- Verbindung zu BigQuery herstellen (DBConnector)
- Tabelle in der Datenbank auswählen (DB Table Selector)
- Datenbank Query eingeben (DB Query)
- Datenbank Query ausführen (DB Reader)
- Das Ergebnis in eine Excel Datei schreiben
Achtung: Wenn ihr die Verbindung zu Google BigQuery herstellt, erscheint ein Pop-up mit einer URL. Diese müsst ihr in eurem Browser aufrufen mit dem ihr in BigQuery eingeloggt seid. Führt dort den üblichen Authentifizierungsprozess durch. Den Bestätigungscode kopiert ihr in das Pop-up Fenster und bestätigt mit OK.
Puuuuuh ヽ(✿゚▽゚)ノ 🎉 geschafft! Wir sind am Ende angekommen 🏆🏆🏆
Wir können nun:
– ScreamingFrog per Batch-Datei steuern und automatisch ausführen.
– ScreamingFrog Crawls mittels KNIME bearbeiten und in Google BigQuery laden.
– Daten aus Google BigQuery mit KNIME abfragen und auswerten.
Was kommt als nächstes?
Als kleines Projekt für die SEOkomm hat dieses Setup wunderbar funktioniert. Natürlich gibt es einige Next-Steps, die möglich sind um alles zu professionalisieren. Vor der SEOkomm2019 war dafür leider keine Zeit mehr.
- ScreamingFrog Crawls in der Cloud
- Lokale Crawls sind stets fehleranfällig. Ein denkbares Setup ist den Frosch auf eine Amazon Ec2 zu installieren und die Crawls in ein angeschlossenes S3 Bucket zu speichern.
- KNIME Prozesse auf dem KNIME Server
- Die bestehenden Worfklows können direkt auf einem KNIME Server ausgeführt werden.
- Sowohl ETL Prozesse als auch Analysen lassen sich somit von allen Anwendern nutzen.
Noch ein kleines ToDo für dich…
Du hast Lust noch etwas zu experimentieren? Nun… du hast deine Crawl-Daten in Google BigQuery. Nichts leichter als jetzt ein Google Data Studio Dashboard anzuschließen und deine Daten auszuwerten!
Hier ein Beispiel der fahrrad.de E-Bike Daten: Google Data Studio für Fahrrad.de
Ich hoffe dir hat der Artikel gefallen und du konntest etwas mitnehmen. Ob du nun im SEOkomm2019 Vortrag warst, oder einfach nur so interessiert an KNIME, ScreamingFrog und BigQuery bist. Wenn dir gefallen hat was du gelesen hast oder Fragen aufgekommen sind, freue ich mich über einen Kommentar. Gerne auch einen Screenshot deines Data Studio Dashboards mit Crawl-Daten ✌😎

Johannes Kunze
SENIOR CONSULTANT & PARTNER
Da ich in meiner Laufbahn stets an technischen Bereichen interessiert gewesen bin, hatte ich in meinem Berufsleben durchweg mit Informationstechnologien und dem Internet zu tun. Nach meinem Studium der Informationswissenschaften war der Schritt ins Online-Marketing mehr oder weniger vorprogrammiert. Während dieses Studiums wurde eine komplett andere Denkart in den Mittelpunkt gerückt, die besonders hilfreich für den Bereich SEO ist, nämlich die der Suchsysteme. Neben der Optimierung für Suchen spielen Datenanalysen und datenunterstützte Entscheidungsfindung in all meinen Projekten eine zentrale Rolle.




4 Kommentare:
Hi Johannes,
vielen Dank für das Tutorial (y)
Ich habe mich mal hingesetzt und bin alles so durchgegangen und komme auch auf ein Ergebnis. Klappt also alles 🙂
Da ich mit BigQuery sehr wenige Erfahrungen hatte, dauerten manche Schritte hier ein wenig länger als gedacht, aber das wird sich bestimmt demnächst lösen lassen.
Werde mal in der nächsten Zeit mit KNIME/SF rumspielen und sicher einige Fragen haben, die ich dann auch hier reinschreiben werde.
LG und weiter so!
Sercan
Hey Sercan,
es freut mich sehr, dass dir der Beitrag gefallen und vor Allem geholfen hat!! Wenn du Fragen hast, immer gerne kommentieren. Ich hoffe ich kann dir dann helfen ;-).
LG Johannes
Ps.: Seit der Version 4.1 von KNIME Analytics gibt es extra Knoten für Google BigQuery. Das Abfragen der Daten ist damit nun einfacher.
Hello Johannes,
echt starkes Tutorial, eröffnet neue Perspektiven, vielen Dank!
Habe versucht, das Ganze unter MacOS zum Laufen zu bringen, und bin dabei über das Problem gestolpert, wie ich die Datei schema.json automatisch erzeugen kann (z.B. in Knime), da meine Tabelle etwas anders aussieht als bei dir. Wie machst du das an der Stelle?
Viele Grüße und vielen Dank,
Max
Hey Max,
vielen Dank. Es freut mich, dass dir der Beitrag gefallen hat!
Tatsächlich habe ich die JSON Datei für das BigQuery Schema manuell erstellt. Ich wusste, dass es sich während des Projekts nicht ändern wird. Der Aufwand für eine automatische Erstellung hat sich nicht gelohnt.
Du könntest eine Mapping-Datei erstellen, in der du die von BigQuery unterstützten Datentypen mit denen aus KNIME verknüpfst und damit dann aus der Tabelle, bzw den Spalten und Datentypen in KNIME eine JSON-Datei für das Schema in BigQuery erstellen.
Wenn du aber nicht bei jedem Durchlauf ein anderes Schema benötigst, würde ich mir die Mühe nicht machen. Wenn es nur gelegentlich nötig ist, würde ich wahrscheinlich einfach gelegentlich ein neues Schema erstellen. Zudem ist BigQuery bei CSV und JSON Dateien auch recht gut darin, selbstständig die Datentypen zu erkennen. Das nutze ich gerade in einem anderen Projekt und es funktioniert sehr gut.
Ich hoffe das hilft dir weiter 🙂
Viele Grüße
Johannes