
Verlage erhalten mehr als die Hälfte des Traffics aus Google Discover. Damit ist Discover die wichtigste Traffic-Quelle des Google-Kosmos geworden und hat sogar Google News abgehängt. Der Report von Google ist jedoch ungeeignet, um zu Traffic-Bringern Aussagen zu treffen. Wir haben eine Lösung entwickelt, um zu verstehen, welche Themen in Discover für einen Verlag funktionieren.
Der Artikel beschäftigt sich mit den folgenden Fragestellungen zu Google Discover:
- Wie identifiziert man Traffic aus Discover im Gegensatz zu organischem Traffic und Traffic aus Google News?
- Wie funktioniert Google Discover und was bedeutet dies für die redaktionelle Arbeit?
- Wie analysiert man Traffic aus Discover und welcher Weg ist der am besten geeignete Weg?
- Welche Schlüsse zieht man aus der Analyse?
Google Discover und der plötzliche Traffic-Anstieg oder wie alles begann
Obwohl es den Dienst Google Discover schon in ähnlicher Form als Google Now und später Google Feed gab, ist es erst mit dem immensen Traffic-Anstieg im Jahr 2018 interessant geworden, einen näheren Blick auf die Daten zu werfen.
Hatte Google Now nur die Vorlieben des Nutzers auf der Basis seiner Suchanfragen berechnet und zeigte dem Nutzer so aktuelle Informationen, so konnte Google Feed darüber hinaus schon eine individuelle Schlagzeile anzeigen.
Google Discover bietet darüber hinaus die Möglichkeit, dass der Nutzer für ihn persönlich spannende Themen in Discover entdecken kann. Dazu muss er auf seinem Android nur nachrechts wischen.
War Google Now darauf ausgerichtet, aktuell und relevant zu sein, so hat sich der Focus von Google Discover deutlich zur Relevanz hin verschoben. Auch etwas ältere Informationen, wir sprechen hier von wenigen Tagen, werden angezeigt, wenn die Relevanz hoch ist.
Momentan verteilt sich der Traffic bei Verlagen folgendermaßen: Der überwiegende Teil des Traffics kommt aus Discover. Darauf folgt der Traffic aus Google News und erst ein letzter Teil kommt aus der organischen Suche. Dabei kann der Discover-Traffic 50 bis zu 90 Prozent des gesamten Traffics aus dem Google Kosmos ausmachen.
Verwundern muss einen das nicht. Auf jedem Android-Smartphone ist Google Discover vorinstalliert und wird automatisch angezeigt, wenn der Nutzer auf dem Display nach rechts wischt. Bei einem Marktanteil von um die 80 Prozent von Android-Telefonen am gesamten Smartphone-Markt in Deutschland ist das eine beträchtliche Größe und bedeutet daher eine enorme Reichweite. Daher betrachten wir Discover als eine der drei Säulen des Google-Traffics für Verlage.

Google Discover und wie es funktioniert – Bedeutung für SEO und Redaktionen
Für Redaktionen ist zunächst einmal interessant, welche Inhalte, also Artikel, den Traffic aus Discover ausmachen. Eine Analyse der Daten aus Google ist unerlässlich. Die Daten aus der Google Search Console sind dürftig. Zur Interpretation des Discover-Traffics sind sie kaum nutzbar. Ebenso schwach sieht es mit den Daten in Google Analytics aus. Es werden keine Daten gezeigt, die nach Discover-Traffic sortiert sind, wenn nicht ein entsprechender Filter in Analytics eingerichtet wird. Wie dieser funktioniert, hat Valentin Pletzer beschrieben.
Die interessante Frage für Publisher bleibt: Zu welchen Themen bekomme ich Traffic auf meine Seite?
Dazu muss man auf die Funktionsweise von Discover schauen: Discover ermittelt für die Vorlieben der Nutzer passende Entitäten – also klar definierte Bezeichner für ein Thema.
Dazu nutzt Google das Suchverhalten der Nutzer in Google, aber auch das Nutzungsverhalten auf YouTube und auf Google Discover selbst. Ebenso spielt der Ort, an dem man sich befindet, eine große Rolle. Dies ist vor allem für lokale Nachrichten oder Events relevant.
Es wird vermutet, dass Google das Browsingverhalten der Nutzer ebenfalls berücksichtigt.
Die Artikel der Publisher werden ebenfalls mit Entitäten annotiert. Auf diese Weise erfolgt die Zuordnung von Artikeln zu den Nutzern. Dabei kann man feststellen, dass Publisher für bestimmte Entitäten, also Themen, eine Autorität von Google zugeschrieben bekommen.
Aber für welche Themen habe ich als Publisher eine Autorität in Discover?
Google vergibt an Webseiten Autoritäten. Das bedeutet, dass bestimmte Seiten zu einigen Themen hohe Reputation und Ansehen zugeschrieben bekommen. Diese Autorität spielt eine Rolle bei der Positionierung in Discover. Daher ist es für Redaktionen wichtig zu wissen, für welche Themen man Autorität zugewiesen bekommt. Dann kann die Redaktion entscheiden, welche Themen immer wieder gut funktionieren und so in Discover erscheinen. Ebenso kann eine Redaktion sicherer entscheiden, welche Art von Themen für ein Republishing geeignet sind.
Um an interpretierbare und nutzbare Daten zu kommen, haben wir die Daten des Discover Leistungsreport aus der Google Search Console extrahiert und die Slugs der Artikel an das Natural Language Tool von Google (NLP-API) gesendet.
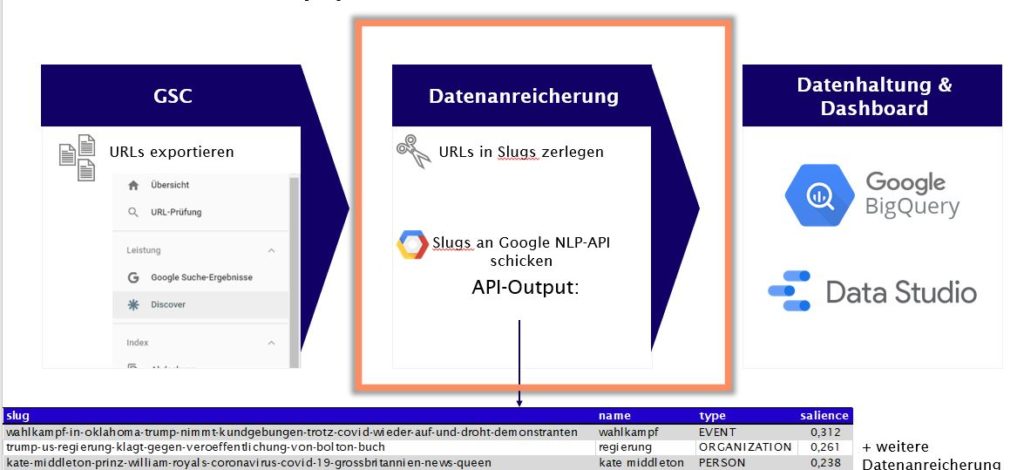
Das funktioniert im Verlagsbereich sehr gut, da der Titel des Artikels bzw. der Seite am Ende der URL steht und man in der Regel relevante Informationen zu dem Artikel bekommt. Wir fragen also von Google ab, welche Entität Google einer URL zuordnet.

Die Daten aus dieser NLP-API-Abfrage reichern wir im Anschluss mit weiteren Informationen wie Artikel-ID, N-Grams, Verben und Adjektiven an und laden dann alles in Google Big Query. Anschließend überführen wir diese aggregierten Daten in ein Data Studio Dashboard. Mittels des Dashboards ist es nun möglich die Daten zu interpretieren.
KI und das echte Leben – Probleme bei der Auswertung der Daten
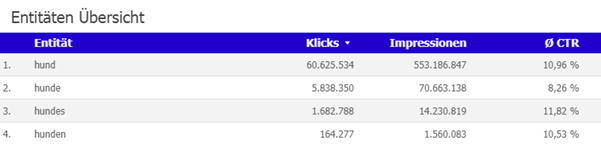
Das Problem besteht noch immer darin, dass man oftmals nicht eindeutige oder zu wenig präzise Daten von der NLP-API bekommt. So sind „Hund“ und „Hunde“ als zwei verschiedene Entitäten aufgeführt, dabei handelt es sich nur um Singular und Plural desselben Begriffs. Die Worte meinen auch nichts Unterschiedliches.
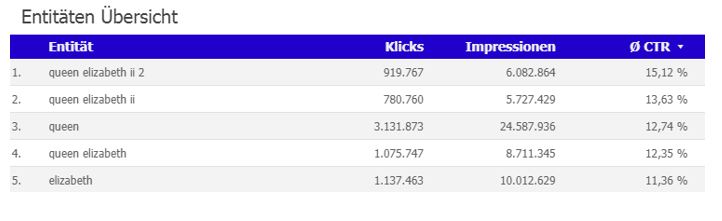
Ebenso bekommt man gleich mehrere Entitäten ausgeworfen, die das Gleiche meinen. So kann das Tool noch nicht entscheiden, dass mit „queen elizabeth“, „queen elizabeth 2“ und „elizabeth“ immer die Regentin des britischen Königshauses gemeint ist.
Ein weiteres Problem ist, dass man in manchen Fällen gar keine Entität ausgeworfen bekommt. So ist der Titel „Michael Wendler: Schockierende Beichte – Ex Claudia Norberg muss nun tatsächlich …“ in die folgenden Entitäten zerlegt worden: „Bilder“ und „michael wendler claudia norberg ex frau dschungelcamp laura mueller playboy“. Damit lässt sich schwer gut arbeiten.
Das Fazit, das man daraus ziehen muss, ist, dass man bei der Interpretation der Daten aus der NLP-API ein gewisses Grundrauschen annehmen muss. Zudem braucht es eine breitere Datenbasis.
Daher haben wir probiert, ob Volltext und Description eine bessere Ausgangsbasis für die Extraction der Entitäten sind. Aus „Michael Wendler: Schockierende Beichte – Ex Claudia Norberg muss nun tatsächlich …“ kommen bei der Auswertung der Description immerhin die Entitäten „geständnis“, „dschungelcamperin“, „ex“, „claudia norberg“, „michael wendler“, „zwei Millionen“ heraus. Das ist zwar schon eine deutlich stärker ausdifferenzierte Auswertung, hilft jedoch nur bedingt weiter. Denn das Ziel ist ja, das Interesse des Lesers zu erkennen. Aus der Entität „ex“ lässt sich kein Interesse ablesen und auch bei „zwei Millionen“ ist die Interpretationsmöglichkeit unendlich.
In der Auswertung des Volltextes erkennt die NLP-API die folgenden Entitäten: „ex“, „nachricht“, „michael wendler“, „claudia norberg“, „dschungelcamperin“, „gestaendnis“, „foto“, „beichte“, „kamera“ und „paar“. Zwar sind dies deutlich mehr Entitäten, die Ergebnisse der Abfrage helfen jedoch nicht unbedingt weiter, wenn man Hinweise auf die Themen erhalten will, die einem Traffic bringen.
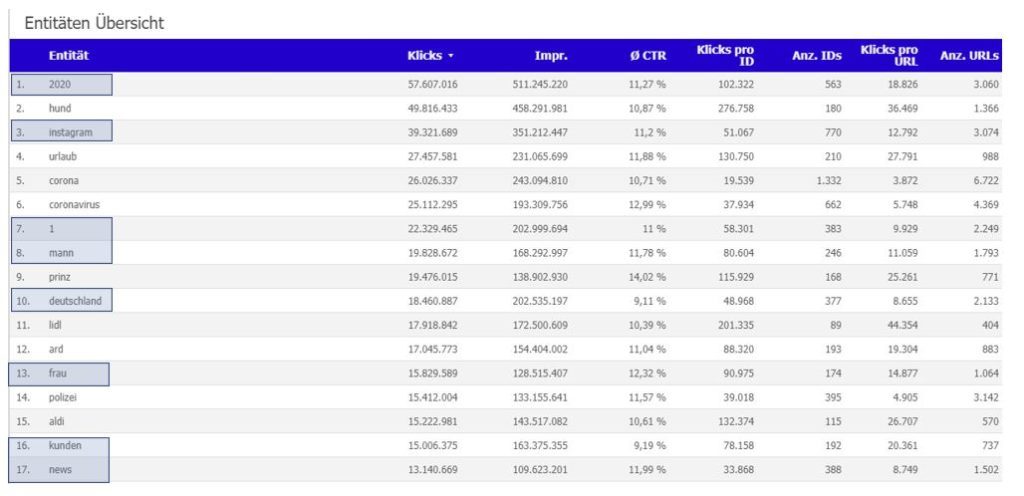
Viele Entitäten, doch wie findet man nützliche Entitäten?
Unsere Versuche haben gezeigt, dass man Entitäten auf drei verschiedenen Wegen abfragen kann:
- slug der URL
- Description
- Volltext
Die Frage ist nun jedoch, mit welcher Methode man am besten zum Ziel kommt: Benennung der Themen, die Traffic bringen. Die Abfrage der Entitäten über den Slug oder die Description liegen in der Korrektheit gleich auf. Jedoch ist es ungleich aufwändiger, die Entitäten aus der Description zu ziehen, ohne dabei gleichzeitig ein wesentlich höheres Rauschen zu erzeugen. Deshalb haben wir uns für den Slug entschieden. Denn für die Identifikation von Discover-Traffic gilt die Gleichung:
Slug = nützliche Entitäten + geschonte Ressourcen
Von der Theorie in die Praxis – Wie wendet man die Erkenntnisse an?
Sind bestimmte Themen und Namen anhand der Slug-Analyse und der Daten aus Discover definiert, dann kann man für die Redaktionen ein Dashboard anlegen, das genau diese Themen beobachtet und mit dessen Hilfe man Schlussfolgerungen ableiten kann.
Um aus der Analyse einen Gewinn ziehen zu können, geht man in drei Schritten vor. Zunächst schaut man, welche Entitäten für welches Thema stehen.
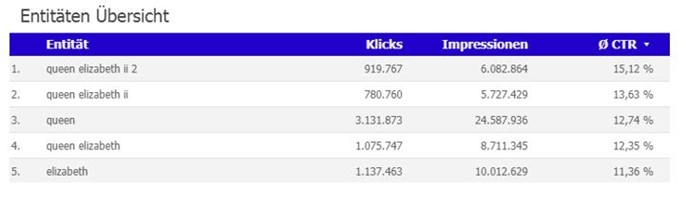
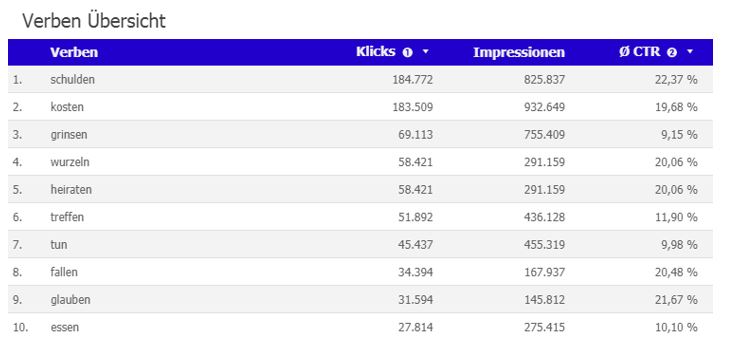
Danach schaut man sich an, welche Verben den Entitäten sinnvoll zugeordnet werden können. Dabei sollte man beachten, dass es sowohl klickattraktive Verben als auch sinnvolle, also passende Verben gibt.
Im Anschluss wirft man einen Blick auf die Adjektive, die man der Entität zuordnen kann. Auch hier gilt es wieder zu kategorisieren. Es gibt auch hier klickattraktive Adjektive und sinnvolle, also passende Adjektive. Ideal ist es natürlich, wenn beide Kategorien zutreffen.
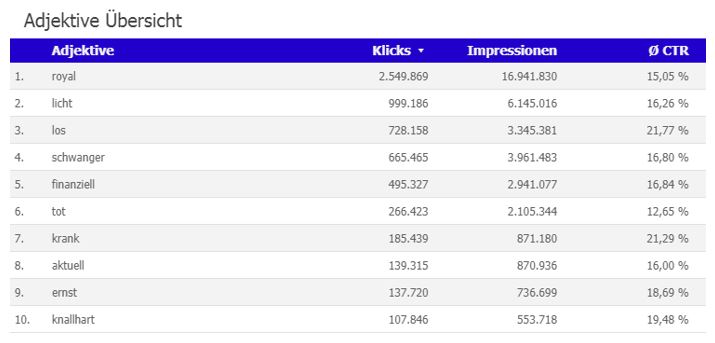
Im Falle der Entität „Queen Elizabeth 2“ ist sicherlich die Zuordnung von „royal“, „finanziell“, „tot“, „krank“, „aktuell“, „ernst“ und „knallhart“ sinnvoll. Wir können mit Sicherheit annehmen, dass das Adjektiv „schwanger“ nicht zu der Entität „Queen Elizabeth 2“ passt.
Eine Überschrift wie „Queen trifft knallharte Entscheidung: Keine finanziellen Zuwendungen mehr für die Ex-Royals Prinz Harry und Meghan Markle“ wäre also klickattraktiv. Oder andersherum betrachtet: Ein Artikel mit dem Thema „Queen trifft knallharte Entscheidung: Keine finanziellen Zuwendungen mehr für die Ex-Royals Prinz Harry und Meghan Markle“ ist ganz offensichtlich interessant für Leser. Kann das Thema also noch einmal besetzt werden oder eine Regel für andere Berichterstattung über die Royals ausgemacht werden? Oder sind die Royals immer ein Thema, egal, welcher Aspekt unter die Lupe genommen wird?
Republishing-Vorgehen für Google Discover
Republishing- Prozesse kommen eigentlich aus der Arbeit mit und für Google News. Korrekterweise geht man bei einem Republishing für Google News-Artikel so vor, dass man den Artikel um den Titel abwandelt, gegebenenfalls Artikel um aktuellen Inhalt erweitert und das Publikationsdatum aktualisiert.
Ein anderes Format, das auf ein ständiges Republishing ausgelegt ist, stellt der Newsticker dar. Hier wird kontinuierlich der Inhalt erweitert, neue Überschriften gefunden und das Update-Datum aktualisiert. Dadurch, dass sich oft der Title ändert und damit auch die URL, erkennt Google das aktualisierte Nachrichten-Stück wieder als einen quasi neuen Inhalt und bringt ihn in die News-Box.
Aber funktioniert Republishing auch in Discover? Ja, der Traffic kann über ein paar Tage gehalten werden.
Für Redaktionen ist die Frage interessant, wie oft man wiederveröffentlichen sollte. Unseren Beobachtungen nach hält sich der Traffic nicht längerfristig hoch, auch wenn kontinuierlich wiederveröffentlicht wird.
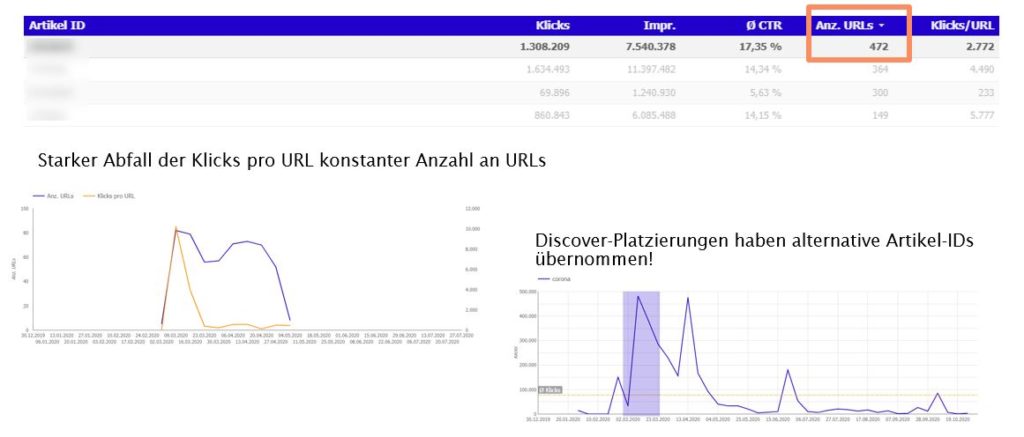
Dies haben wir durch den Vergleich der Anzahl der URLs im Gegensatz zur Performance der Artikel-ID festgestellt.
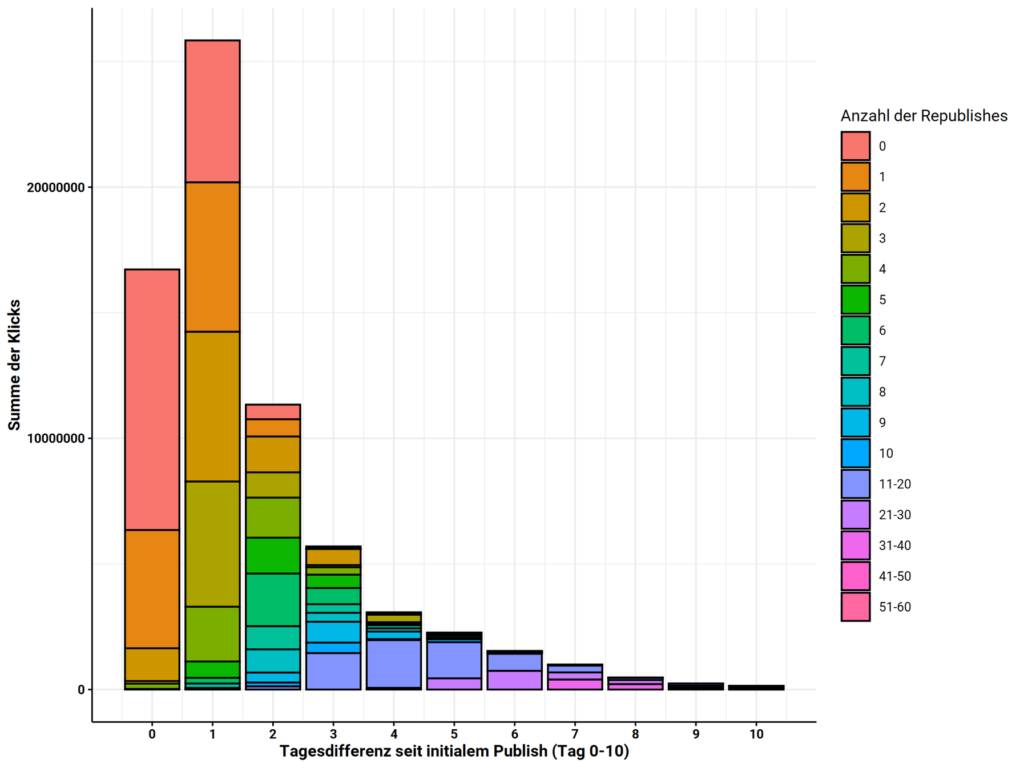
Daraus schließen wir, dass ein Republishing nicht über die Anzahl zehn hinausgehen sollte.
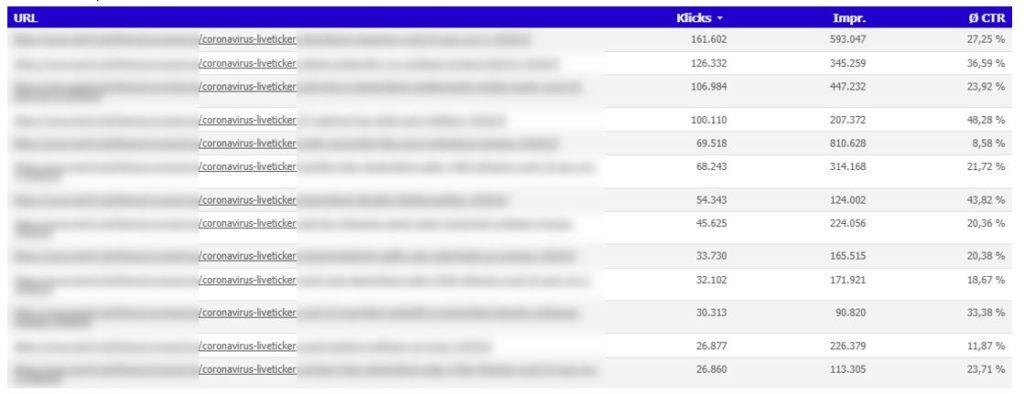
Was erkennen Redaktionen mit dem get:traction-Dashboard für Discover?
In unserem Discover-Dashboard erkennen Redaktionen, welche Themen den Traffic erzeugt haben und wie lange dieser Traffic-Zufluss für ein Thema angehalten hat. In dem hier gezeigten Fall, der 472 mal wiederveröffentlicht wurde, kann man erkennen, welches Thema sich so lange hält: Ein Corona-Newsticker.
Grundsätzlich muss man jedoch genau unterscheiden, für welchen der Google-Feeds man Republishing macht. Für Google News braucht es ein sehr schnelles und häufiges Republishing, das dem Tagesgeschehen angepasst ist. Für Republishing in Google Discover hat man dagegen ungleich mehr Zeit. In Discover können sich Artikel 4 bis 48 Stunden halten.
Das bedeutet, dass eine Redaktion getrost schauen kann, welche Themen am Vortag gut gelaufen sind und sich dann die identifizierten Themen zur Wiederveröffentlichung vornehmen.

Um das Republishing konsequent zu nutzen, sollte daher ein eigener Redakteur mit der Aufgabe befasst sein und ein konkreter Prozess definiert werden. Einen solchen Prozess haben wir wie folgt skizziert:
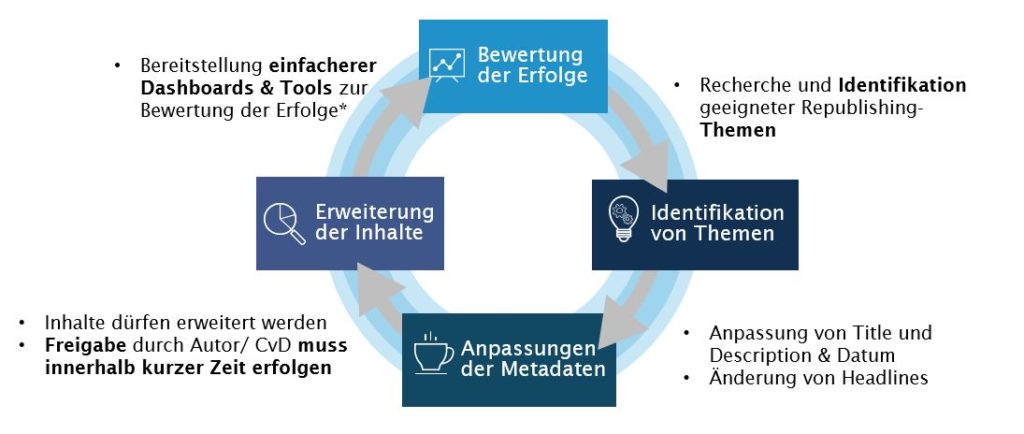
Der Prozess für regelmäßiges und Daten-basiertes Republishing sollte folgendermaßen aussehen:
- Zunächst definiert man die Themen fürs Republishing.
- Danach erfolgt die Anpassung der Metadaten, also von Title & Description und dem Publikationsdatum. Zudem sollte die Headline geändert werden.
- Sollte eine Erweiterung der Inhalte notwendig sein – weil sich dieser aus der aktuellen Lage ergibt – muss ein schneller Freigabeprozess durch den ursprünglichen Redakteur sichergestellt sein.
- Eine Bewertung der Erfolge muss mit einfachen Dashboards und Tools erfolgen. Aus dieser Bewertung sollten Erfahrungen und Erkenntnisse zu Themen und Bildauswahl für zukünftiges Republishing gezogen werden.
Darüber hinaus funktionieren auch Evergreen-Inhalte in Discover. Alle Artikel, die zum Beispiel in das Ressort Ratgeber fallen, eignen sich fürs Republishing und können in Discover erscheinen. Auffällig ist jedoch, dass alle Stücke, also Artikel, nicht mehr als ein bis zwei Tage alt sind. Hier muss eine eigene Strategie für das Republishing im Ratgerberbereich erarbeitet werden.
Zumindest für saisonale Themen sollte dieses problemlos möglich sein.
Betrachtet man die drei Säulen des Google-Traffics, dann ist klar, dass jeder Google-Feed oder Dienst eine eigene Strategie braucht, um jeweils erfolgreich zu sein. Es braucht teilweise unterschiedliche Prozesse, Tempi und Herangehensweisen.
Unsere Erkenntnisse aus der Analyse der Discover-Daten ist daher, dass
- man die Daten aus der GSC anreichern muss, um sie interpretierbar zu machen.
- korrekte Entitäten-Erkennung nicht immer eine nützliche Entitäten-Erkennung ist.
- Weg der Entitäten-Erkennung abhängig ist von Ziel und Datenbasis.
- Adjektive und Verben leicht klicktreibend sein können.
- Republishing für Discover nur im Zeitraum von sieben Tagen sinnvoll ist.
Was lernen Redaktionen aus dieser Analyse?
Themen, die in einer Redaktion funktionieren, also oft und langanhaltend geklickt werden, sollten gestärkt werden. Ebenso sollten Formulierungen oder ein bestimmtes Vokabel-Set definiert und häufiger verwendet werden. Auch wenn Google clickbait verhindern möchte – es wird nicht sanktioniert. Aber vielleicht sanktioniert der Nutzer, wenn er immer wieder enttäuscht wird. Auch das gehört zu den Dingen, die eine Redaktion beobachten und aus denen man lernen muss.
Darüber hinaus sollte geprüft werden, wie sich eine bestimmte Art der Bildsprache auf die CTR auswirkt. Hier sollte man messen und bewerten und aus den Schlüssen eine Strategie entwickeln, um langfristig erfolgreich mit Discover zu arbeiten.
Mehr zu dem Thema „Discover-Traffic analysieren“:
Präsentation „Discover-Traffic analysieren“ auf dem SEO-Day 2020.
Klicken Sie auf den unteren Button, um den Inhalt von www.slideshare.net zu laden.
Vortrag „Discover-Traffic analysieren“ auf dem SEO-Day 2020.

Jens Fauldrath
Geschäftsführender Gesellschafter
Ich habe von 2006 bis 2012 das SEO-Team für t-online.de aufgebaut. Dabei war es essenziell, Redaktion, Produktmanagement und IT gleichermaßen zu berücksichtigen und in den Veränderungsprozess einzubinden. Dieses haben wir erreicht, indem wir die vorhandenen Prozesse erhoben und SEO möglichst aufwandneutral in diese integriert haben




